
ACID vs. BASE: Transaction Models Simplified
Issue #23 of "System Design Interview Roadmap" - Part II: Data Storage
Subscribe to Access Source code repo Trusted by 42000+ Engineers.
I was on a call with a team whose e-commerce platform had just experienced a partial outage during their biggest sale of the year. The culprit? An unexpected interaction between their payment and inventory systems when data
base connections were overwhelmed. "We thought we understood transactions," the lead developer told me, "but when the system was stressed, money disappeared, and customers were charged for out-of-stock items."
This scenario plays out more often than you'd think, and it often stems from a fundamental misunderstanding of transaction models. Today, we'll demystify the eternal database debate: ACID vs. BASE.
The Transaction Dilemma
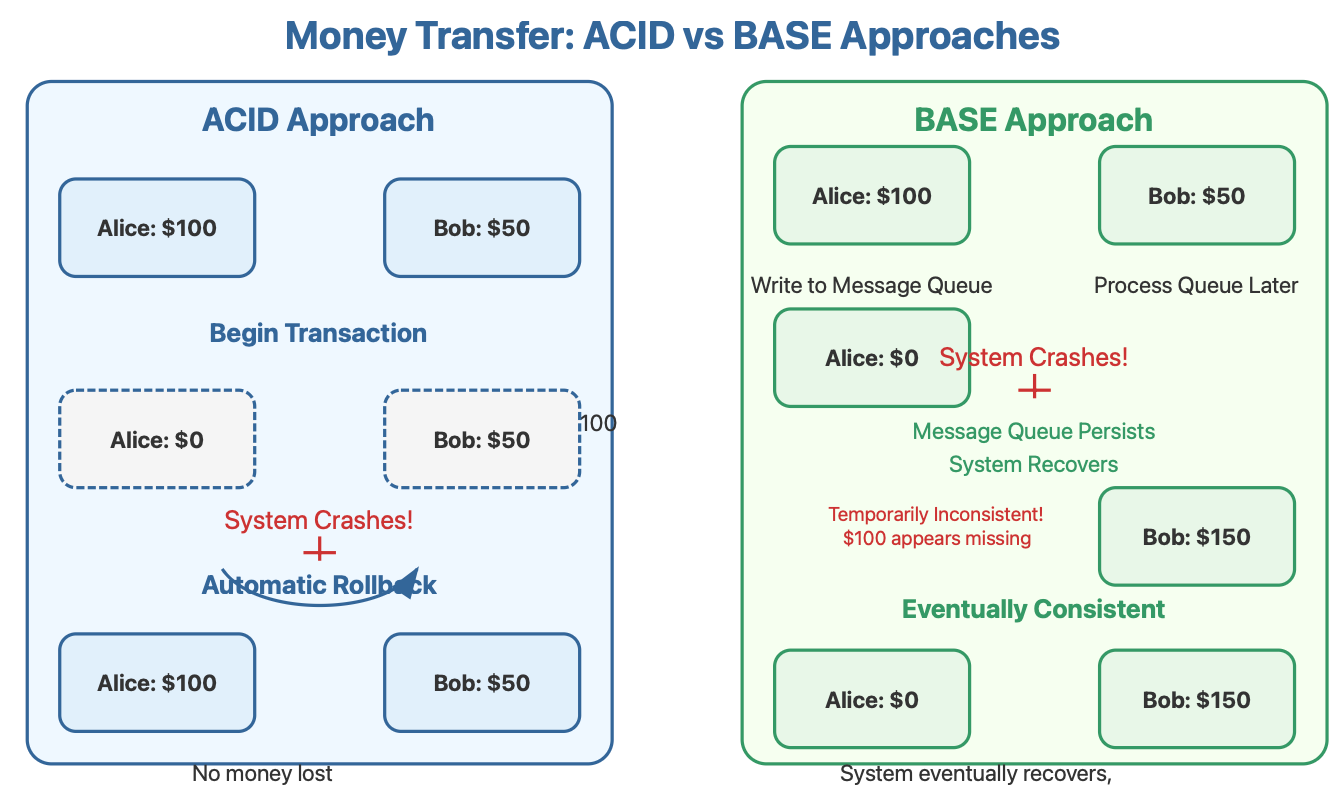
Imagine you're designing a money transfer system. Alice wants to send $100 to Bob. This seemingly simple operation requires two critical steps:
Deduct $100 from Alice's account
Add $100 to Bob's account
What happens if your system crashes between steps 1 and 2? Alice loses money, Bob never receives it, and you have an accounting nightmare. This is why we need transaction models to ensure data integrity.
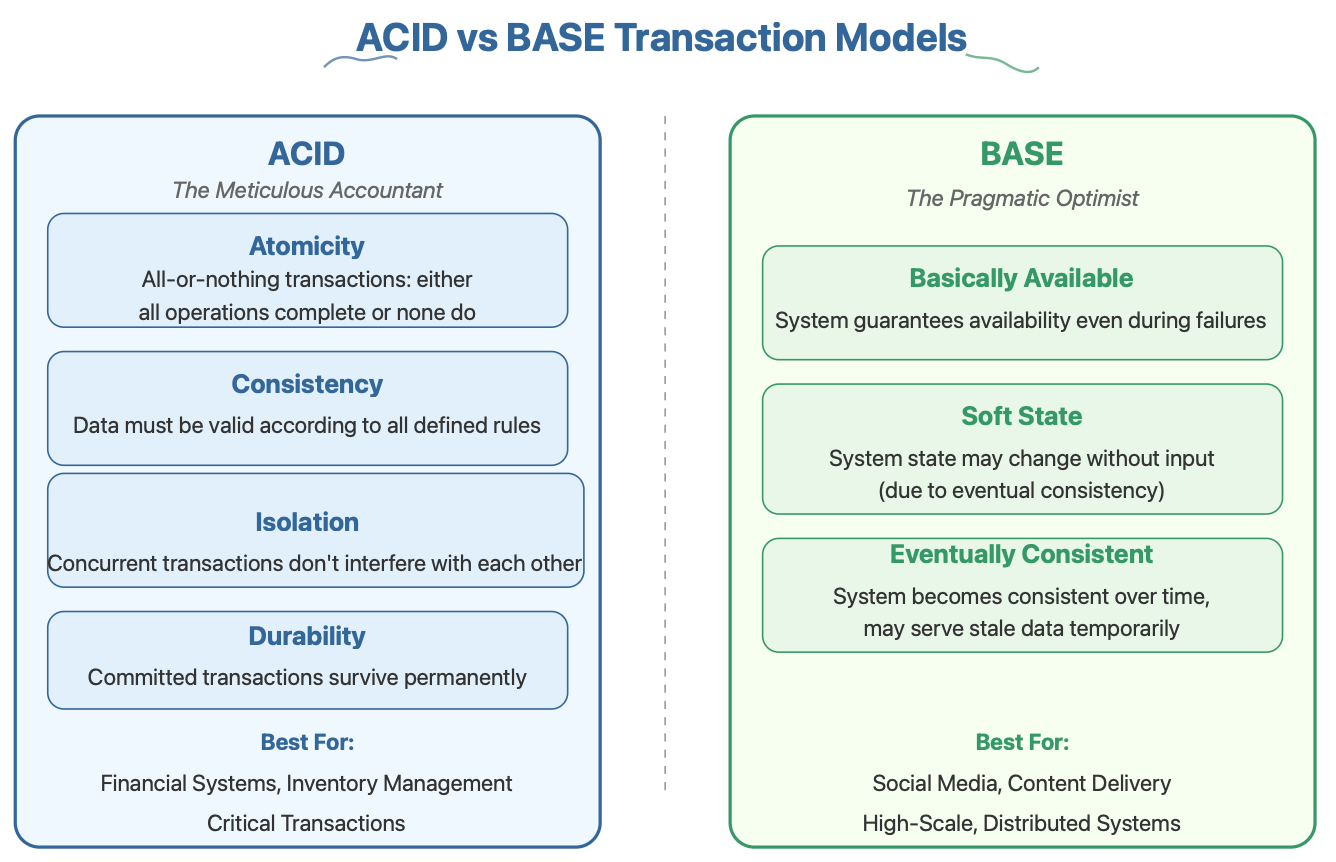
ACID vs. BASE: A Visual Comparison
Money Transfer Example: What Happens When Things Fail
The Hidden Trade-offs Nobody Talks About
Most resources stop at definitions, but let's go deeper into the nuances that make real-world decisions complex:
ACID's Unspoken Weaknesses
Coordination overhead: The mechanisms ensuring ACID properties create bottlenecks at scale. Each transaction often requires locks, limiting concurrency.
Default isolation levels: Even "ACID-compliant" databases often sacrifice some isolation for performance. PostgreSQL's default isolation level (Read Committed) doesn't prevent all anomalies like phantom reads.
Hidden costs: Strong consistency requires more hardware resources and introduces latency, especially in distributed environments. This becomes extremely expensive beyond certain scales.
BASE's Subtle Challenges
Reasoning complexity: Developers must build application-level logic to handle inconsistencies, essentially moving complexity from the database to the application.
Mental model shift: Engineers trained in ACID environments struggle with eventual consistency. I've seen teams spend months debugging issues stemming from misunderstanding BASE semantics.
Conflict resolution: Eventually consistent systems can produce surprising behaviors during network partitions or when multiple conflicting updates need resolution.
Making the Right Choice: A Decision Framework
Instead of presenting a false binary, consider these factors when choosing your transaction model:
Data criticality: Does every piece of data need absolute consistency?
Read-to-write ratio: ACID excels with frequent writes, while BASE performs better with read-heavy workloads.
Scale requirements: At what point does your system need to scale beyond a single node?
Geographic distribution: Do you need to operate across multiple regions with low latency?
Business impact of inconsistency: What's the cost of a temporarily inconsistent view? For a bank, catastrophic. For a comment count, negligible.
Hybrid Approaches: The Best of Both Worlds
Modern systems rarely use a pure ACID or BASE approach. Consider these practical patterns:
Command Query Responsibility Segregation (CQRS): Use an ACID database for critical write operations and a BASE database for read-heavy analytics.
Saga Pattern: Break long-running transactions into a series of smaller transactions with compensating actions for failures.
Transactional Outbox: Write to a local transaction log in an ACID database, then asynchronously propagate changes to eventually consistent systems.
The Exercise: Build a Hybrid Transaction Manager
Here's a simplified pseudo-code for a hybrid transaction manager that combines ACID guarantees for critical operations with BASE scalability: