
There are two types of engineers who fail the distributed systems section of a design interview.
The first type doesn’t know what consistent hashing is. The second type knows the definition but can’t explain why modulo hashing fails or what problem consistent hashing actually solves.
The second type fails more often. Knowing the name without the reasoning is worse than knowing nothing, because it telegraphs that you’ve memorized vocabulary rather than understood the underlying problem.
Here’s the underlying problem.
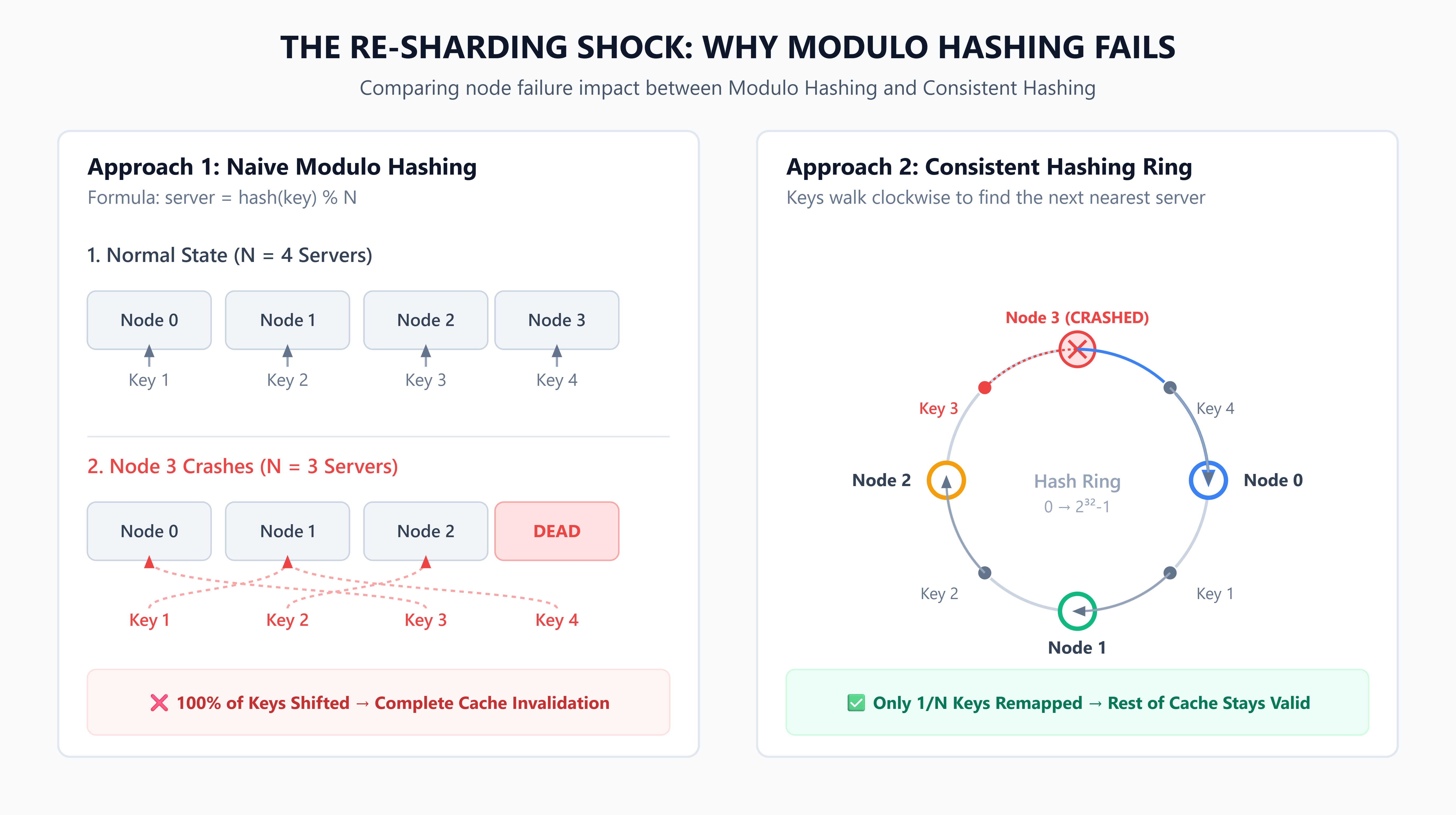
The naive approach: modulo hashing
You have 4 servers and a cache key. You run hash(key) % 4 and get a server number. Simple. Fast. Evenly distributed.
Now one of your 4 servers dies. You have 3 servers. Every single key in the system now maps to a different server, because hash(key) % 3 gives completely different results than hash(key) % 4.
Your cache hit rate drops to near zero. Every miss hits the database. Your database falls over. This is a real production incident pattern.
Same problem in reverse: you add a fifth server to handle load. Every key remaps. Every cache entry is now on the wrong server. The cache is empty until it warms up. If you’re adding a server because you’re under load, this is the worst possible time to invalidate your entire cache.
The consistent hashing solution
Consistent hashing puts both servers and keys on an imaginary ring numbered 0 to 2³². To find which server owns a key: hash the key, find its position on the ring, walk clockwise until you hit a server.
When a server is added or removed, only the keys between the new server and its predecessor on the ring need to move. For N servers, adding or removing one server moves approximately 1/N of the keys. Not all of them. 1/N.
That’s the entire point. The damage from topology changes is contained.
Virtual nodes: the production detail
Naive consistent hashing has a problem: if you hash 4 server IDs onto a ring, they won’t land evenly spaced. Some servers end up owning much more of the ring than others. When one server dies, all of its load dumps onto a single neighbor — the one clockwise from it.
Virtual nodes fix this. Instead of placing each server once on the ring, you place it 100–200 times (with different hash inputs like server1-0, server1-1, server1-2...). Each physical server now has 100–200 positions spread around the ring. Load is distributed evenly. When a server dies, its load spreads across every other server, not just one neighbor.
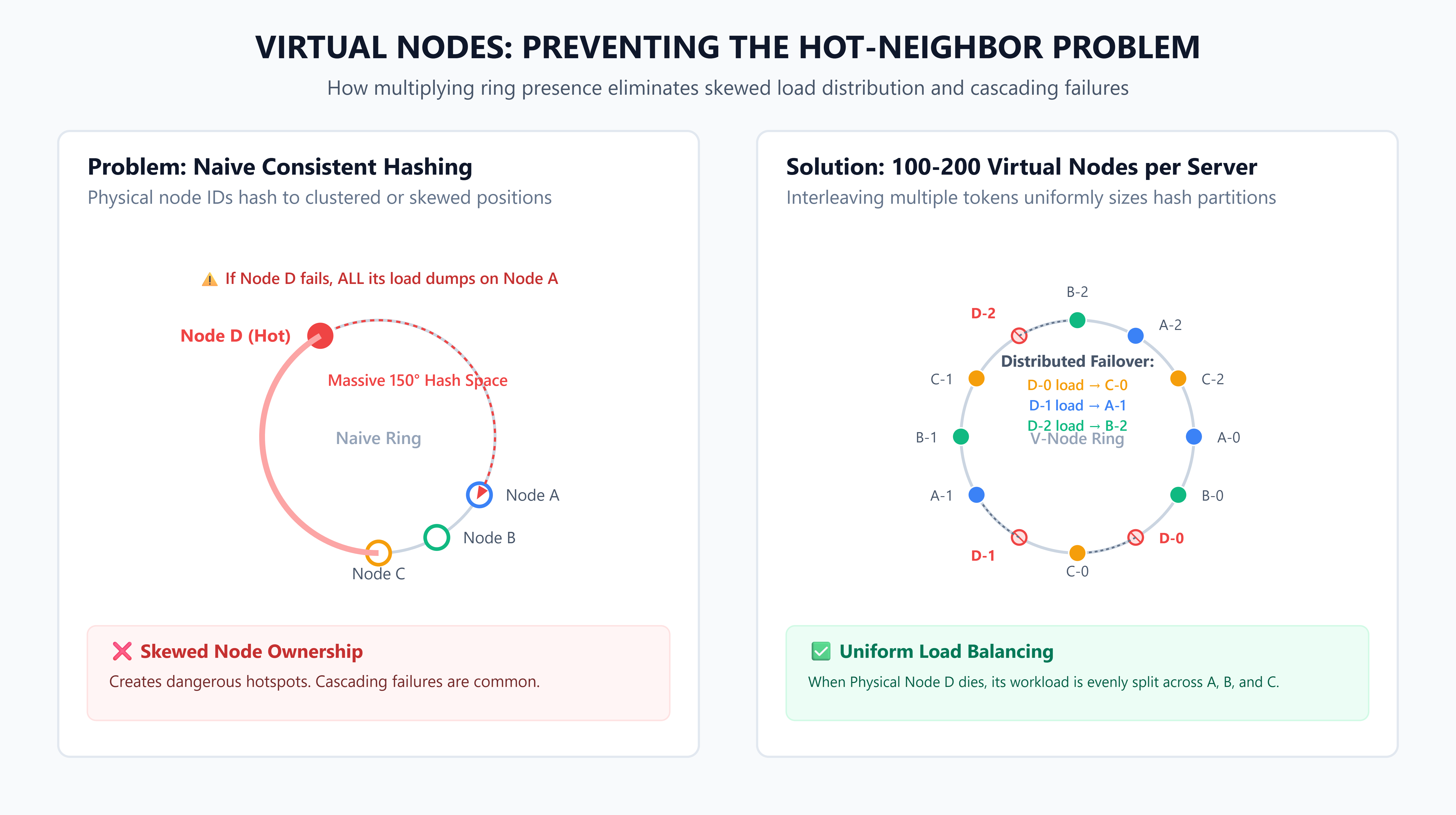
Why this matters in an interview
Consistent hashing shows up in at least 8 of the 52 most common system design questions: distributed caches, rate limiters, database sharding, CDN routing, load balancers, distributed file systems.
When you say “I’d shard by user ID” without specifying how, you’re leaving a gap the interviewer is likely to probe. When you say “I’d use consistent hashing with 150 virtual nodes per server to prevent the hot-neighbor problem on topology changes” — that’s the L5 signal for any infrastructure question.
The rule: anytime you’re distributing data across multiple nodes, consistent hashing is worth naming explicitly. Even if it’s not the exact implementation, mentioning it signals you understand that modulo hashing breaks under real operational conditions.
Subscription link
https://systemdr.systemdrd.com/subscribe
—Sumedh
Want to explore this topic further?
The paid version includes detailed walkthroughs, bonus resources, and hands-on exercises.
The Question Vault has all 52 walkthroughs organized by archetype — so you can see the pattern across questions, not just the surface answer.
Access all 52 Quesstions here