Database Connection Storms: Prevention and Recovery in Production
Article 202 | Section 8: Production Engineering & Optimization
Introduction
Your deployment pipeline just pushed a config change. Within 90 seconds, every microservice that touches your primary database is retrying failed queries. Your monitoring shows PostgreSQL at 100% connection capacity. New connections queue up, then time out. The cascade reaches your cache layer, your message queue, your API gateway. The database itself is fine — idle, even — but nothing can reach it. You have a connection storm, and it will not fix itself.
What Actually Happens During a Connection Storm
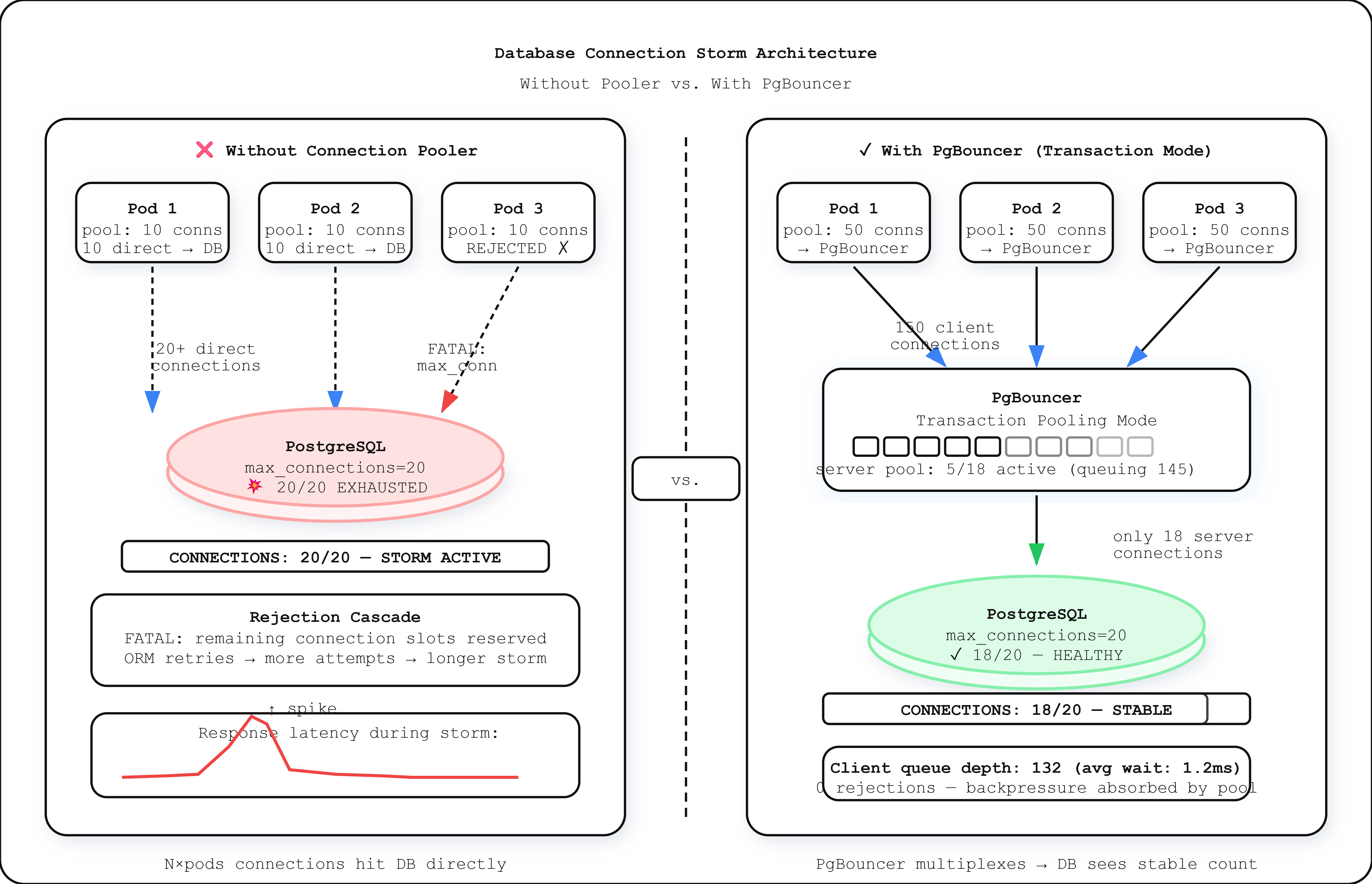
PostgreSQL allocates a dedicated OS process per client connection. Each process consumes roughly 5-10 MB of RAM just for the connection overhead — before executing a single query. PostgreSQL’s
max_connectionsdefaults to 100 on most managed cloud instances and 200 on dedicated hardware configurations. This ceiling is not advisory. When it fills, new connection attempts block until timeout or until an existing connection closes.
A connection storm forms when a large number of clients simultaneously attempt to establish database connections within a window shorter than the connection setup latency. This happens in three primary failure scenarios:
Application restart storms. When a Kubernetes deployment rolls out 40 pods simultaneously, each pod initializes its connection pool. If each pod maintains a pool of 10 connections, you’ve just generated 400 concurrent connection attempts against a database that may accept 200 total. The first 200 succeed. The remaining 200 queue and eventually timeout, causing the pods to retry — extending the storm duration.
Stampede after brief DB unavailability. A 30-second failover to a read replica causes every application instance to detect a lost connection and immediately attempt reconnection. The reconnection attempts are not distributed — they all fire within the same 100-500ms window when the new primary becomes available, creating demand that exceeds capacity by 3-10x.
Pool leak accumulation then sudden release. Long-lived connections that never return to the pool accumulate silently. When the application process eventually restarts (deploy, OOM kill, node rotation), it releases the leaked connections and immediately tries to establish a new full pool — a rapid oscillation between starvation and flood.
The core mechanism: PostgreSQL does not implement admission control beyond hard rejection at max_connections. There is no queuing layer, no backpressure signal, no gradual admission. A connection either succeeds immediately or receives FATAL: remaining connection slots are reserved for non-replication superuser connections, which most ORMs treat as a retryable error, worsening the storm.