
Database Migration Strategies: Zero-Downtime Approaches
The Black Friday Migration: How to Change Your Database While Processing $100M in Sales
From the "System Design Interview Roadmap" series - Real insights from engineers who've scaled systems handling 10+ million requests per second
Picture this nightmare scenario: It's 11:47 PM on Black Friday. Your e-commerce platform is crushing records with $2.3 million in sales every minute. Your database team Slack channel lights up with a message that makes your stomach drop: "We need to migrate the payment database to handle the load. MySQL is hitting its limits."
The CEO's response comes instantly: "How long will the site be down?"
The silence that follows is deafening.
This exact scenario has played out at companies you know and love. Some handled it brilliantly. Others... well, let's just say their customers found alternative places to shop that weekend.
The difference? The successful companies had already mastered zero-downtime database migrations. They could evolve their systems without missing a single heartbeat, even during peak traffic.
Today, I'm sharing the battle-tested strategies that let Netflix migrate their recommendation engine, GitHub transition their core Rails database, and Shopify handle Black Friday migrations without dropping a single transaction.
The Heart Surgery Problem
Zero-downtime migration is like performing heart surgery on a marathon runner without making them stop running. You need to keep the old system pumping data while carefully transitioning to the new one, ensuring no heartbeat is missed.
Most engineers think this is simply about having two databases and flipping a switch. The reality is exponentially more complex.
The Hidden Complexity Everyone Misses:
During migration, you're maintaining distributed state across two systems. Every write operation must be orchestrated to prevent data divergence. Applications need to handle mixed states gracefully - some data exists in the old system, some in the new, some in both.
But here's the killer: if something goes wrong mid-migration, rolling back becomes exponentially harder because you now have two potentially divergent data sources.
The Three Battle-Tested Migration Patterns
After analyzing dozens of successful migrations at companies processing millions of requests per second, three patterns emerge as consistently successful.
Pattern 1: The Blue-Green Theater Production
Think of this like having two identical theater stages. While Act I performs on the blue stage for the audience, the crew prepares Act II on the green stage with perfect lighting, props, and positioning. When ready, the audience seamlessly transitions to the green stage, and blue becomes the backup.
Netflix's Masterstroke: When Netflix migrated their recommendation engine from Oracle to Cassandra, they ran both systems in parallel for months. But here's the insight most people miss: they didn't just copy data. They built sophisticated traffic routing that could automatically detect which database would provide better results for each specific query.
The real breakthrough wasn't the migration itself - it was creating a system smart enough to route traffic based on predicted performance. Their migration became self-improving.
Pattern 2: The Shadow Rehearsal
This strategy works like having a perfect understudy in a theater production. The main actor performs for the audience while the understudy silently rehearses every line, every movement, in the shadows. When transition time comes, the understudy steps into the spotlight seamlessly.
Stripe's Payment Revolution: Stripe used this when migrating their core payment processing database. They shadowed every transaction, every balance update, ensuring their new system could handle identical load patterns. But their genius innovation was "dark reads" - querying both databases but only serving results from the old one, comparing responses to detect inconsistencies.
The hidden insight: They discovered that 99.9% data consistency was actually better than attempting 100% consistency, because the latter introduced latency that impacted user experience more than occasional stale reads.
Pattern 3: The Gradual Takeover
Imagine slowly replacing parts of a car engine while it's running. You don't replace the entire engine at once; instead, you swap components one by one, ensuring each replacement works perfectly before moving to the next.
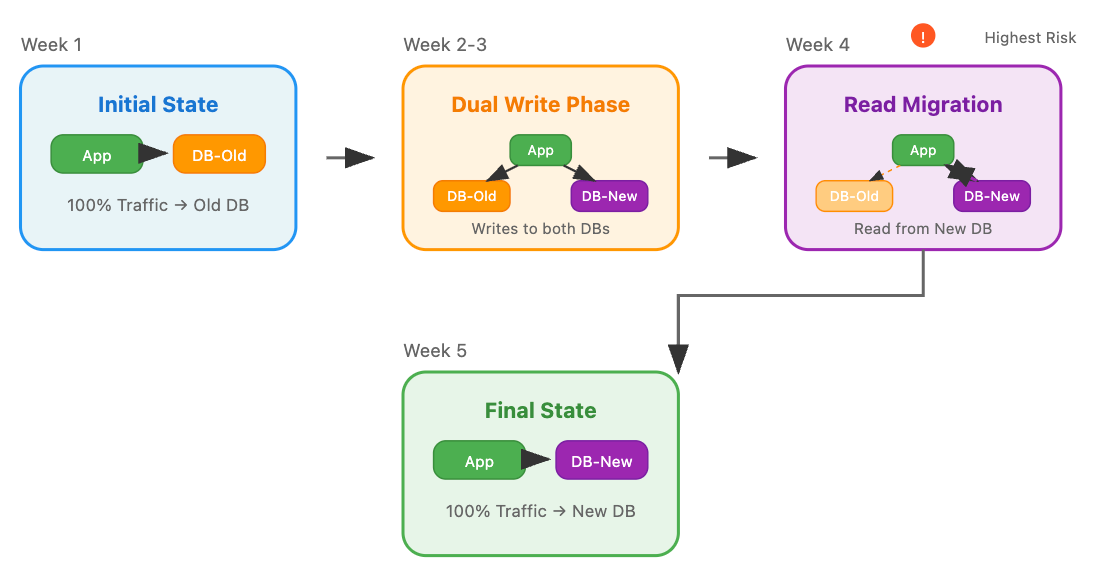
GitHub's Rails Database Epic: GitHub's approach was methodical brilliance. They implemented "dual writes with feature flag reads" - writing to both databases but using feature flags to control which served reads. They prioritized by business impact: internal admin tools first (1% of traffic), then staff accounts (5%), free accounts (25%), and finally paid accounts.
The breakthrough insight: If something went wrong, they wanted it to affect their least critical users first. This business-aware migration strategy became their safety net.
The Instagram Photo Mystery: Migration by User Behavior
When Instagram needed to migrate billions of photos from PostgreSQL to Cassandra, they faced a unique challenge that revealed something profound about large-scale migrations.
Instead of migrating all data chronologically or by database organization, they created a "read-through migration" - a transparent proxy that checked the new Cassandra database first. If data wasn't found, it fell back to PostgreSQL, then asynchronously copied that data to Cassandra.
The Revolutionary Insight: Frequently accessed photos migrated naturally through user behavior, while rarely accessed content remained in the old system until needed. They let their users drive migration priority.
This approach reduced their estimated six-month migration to six weeks because they only needed to migrate active data immediately. The 80/20 rule applied perfectly - 80% of user requests accessed only 20% of their data.
The Airbnb Search Intelligence Revolution
Airbnb's migration from MySQL to Elasticsearch for search functionality provides the most sophisticated case study. They couldn't afford degraded search quality during migration because it directly impacts booking conversions.
Their strategy: run both systems in parallel but use machine learning to determine which would likely provide better results for each query. Initially conservative, the ML model sent most queries to MySQL. As Elasticsearch proved itself, the model gradually increased confidence.
The Self-Improving Migration: They implemented "result quality scoring" - running identical searches against both systems, then using booking conversion rates to determine which provided better outcomes. This data fed back into their routing algorithm, creating a migration system that got smarter over time.
The insight that changed everything: Instead of treating migration as a technical project, they treated it as a machine learning problem. The system learned which database was better at different types of queries and routed accordingly.
The Architecture That Makes It All Possible
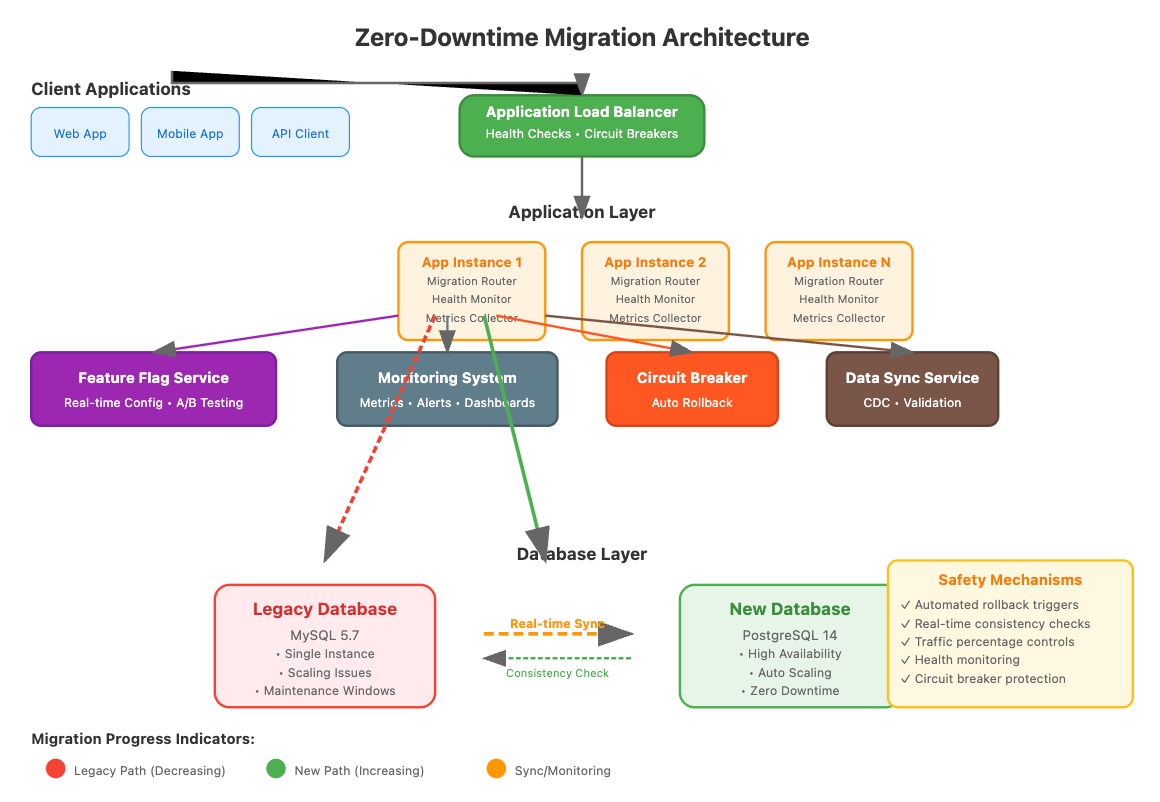
Successful zero-downtime migrations share a common architectural pattern. At the center sits an intelligent routing layer that makes split-second decisions about where to send each request.
This router isn't just a simple load balancer. It's a sophisticated system that:
Maintains user consistency through hash-based routing (same users always go to the same database during migration)
Monitors health continuously with real-time error rate and latency tracking
Implements circuit breakers that fail fast when databases become unhealthy
Handles dual writes to keep both systems synchronized during transition phases
Provides automatic rollback when safety thresholds are exceeded
The router becomes your mission control center, giving you real-time visibility into migration progress and the power to make instant adjustments when conditions change.
The Hidden Safety Mechanisms That Save Systems
Every successful migration story includes safety mechanisms that rarely make it into case studies. These are the unsexy but critical components that prevent small issues from becoming catastrophic failures.
Automatic Rollback Triggers: Set error rate thresholds (typically 1-2% above baseline), latency thresholds (usually 2x normal response times), and data consistency thresholds (0.1% inconsistency rate). When any threshold is exceeded for more than 30 seconds, the system automatically reverts to the previous safe state.
Circuit Breaker Protection: After 3-5 consecutive failures to a database, the circuit breaker opens and routes all traffic to the healthy database. This prevents cascade failures that could bring down your entire application.
Health Monitoring That Actually Matters: Traditional database monitoring focuses on individual database health. Migration monitoring requires understanding the relationship between systems. You need metrics that track data divergence, routing accuracy, and user experience consistency across both databases.
Your Implementation Roadmap: From Theory to Production
Here's how to build migration capability into your systems, even if you don't have an immediate migration need.
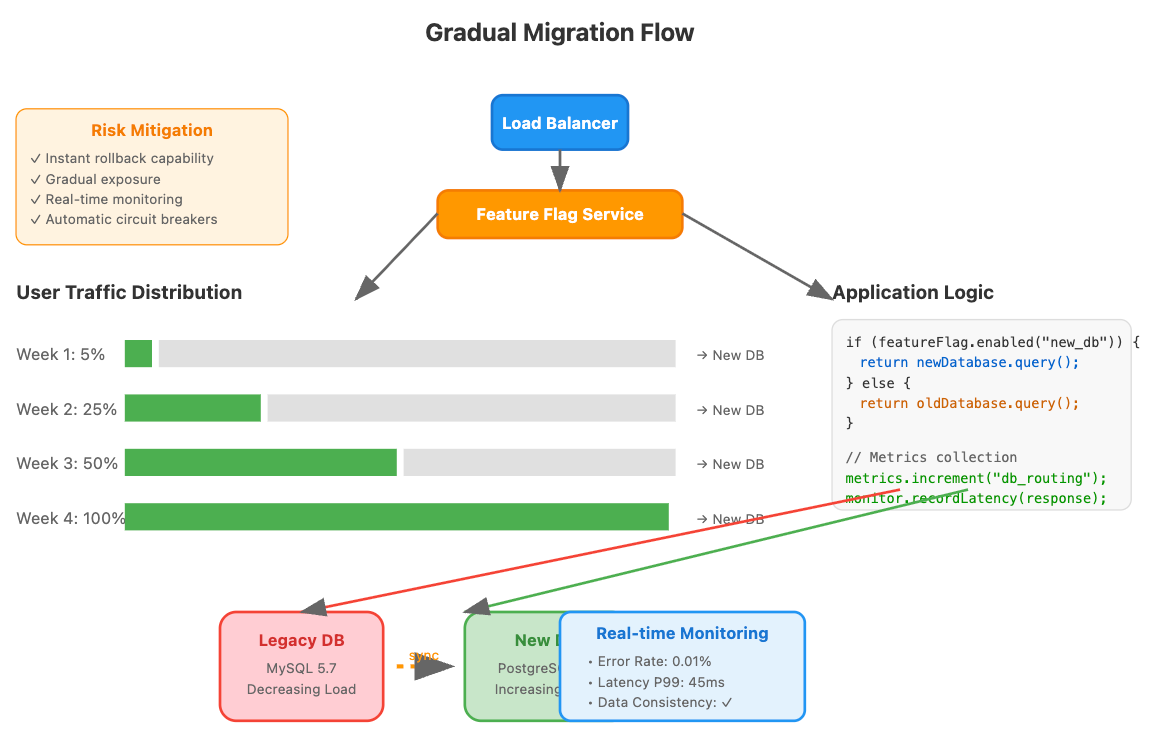
Week 1-2: Foundation Building Implement basic routing infrastructure with feature flag integration. This becomes your primary control mechanism during future migrations. Build comprehensive logging and metrics collection to establish baseline performance data - you need weeks of historical context to understand normal behavior patterns.
Week 3-4: Safety Mechanisms Implement and thoroughly test circuit breaker patterns and automatic rollback mechanisms. These safety nets must be bulletproof. Create data consistency validation logic specific to your data model that can detect meaningful inconsistencies, not just surface-level differences.
Week 5-6: Gradual Rollout Strategy Design user segmentation for gradual rollout considering factors beyond percentage-based routing. You might migrate internal users first, then free tier users, then paid customers. Build monitoring dashboards that show migration progress in business terms, not just technical metrics.
Week 7-8: Testing and Validation Conduct migration rehearsals in staging with production-like data and traffic patterns. Test failure scenarios including network partitions, database failures, and application errors. Validate rollback procedures until they become muscle memory - you should be able to roll back from any migration state within minutes.
Core Implementation: The Migration Router
Let's start by building the heart of our migration system - a smart routing component that can gradually shift traffic between databases while maintaining safety guarantees. Think of this as the conductor of an orchestra, ensuring every component plays in harmony during the transition.
dbmigration.py. - https://github.com/sysdr/sdir/blob/main/dbmigration/dbmigration.py
class DatabaseMigrationRouter:
def should_use_new_database(self, user_id: str) -> bool:
"""Consistent hashing ensures same users get same routing"""
hash_value = int(hashlib.md5(user_id.encode()).hexdigest(), 16)
user_percentage = hash_value % 100
return user_percentage < self.config.new_db_percentage
async def execute_query(self, query: str, user_id: str):
"""Main routing logic with safety checks and fallbacks"""
target_db = self.choose_database(user_id)
if not self.circuit_breakers[target_db].can_execute():
target_db = self.get_fallback_database(target_db)
return await self.execute_with_monitoring(query, target_db)Now let's create a practical bash script that demonstrates these migration concepts in action. This script will help you understand how the migration process works by setting up a simulated environment where you can observe the behavior we've discussed.
🔧 Hands-On Demo Script - Interactive migration simulation you can run locally - See circuit breakers, rollbacks, and health monitoring in action - Perfect for experimenting with migration concepts safely - demo script →
https://github.com/sysdr/sdir/blob/main/dbmigration/setup.sh
The Long-Term Perspective: Building Migration as a Core Capability
The most successful engineering organizations treat migration capability as a core competency, not a one-time project. They build systems with migration in mind from the beginning, making future migrations less risky and more routine.
Consider implementing database abstraction layers that isolate database-specific logic. When your next migration comes (and it will), you'll have the infrastructure in place to execute smoothly.
Build relationships with database vendors and cloud providers before you need them. During critical migrations, having direct access to expert support can make the difference between smooth transition and emergency response.
Document decision-making context, not just procedures. Future migrations will face different constraints, but your decision-making frameworks remain valuable. Capture why you made specific choices, what alternatives you considered, and what you learned from outcomes.
The Moment of Truth
The next time your system needs to evolve - whether it's scaling for growth, adopting new technologies, or improving performance - you'll face the same choice every growing system encounters: evolve or become obsolete.
With zero-downtime migration capabilities, that choice becomes an opportunity rather than a crisis. Your users keep shopping, your revenue keeps flowing, and your system keeps improving.
The companies we studied didn't achieve zero-downtime migrations by accident. They built the capability systematically, tested it thoroughly, and executed it with discipline.
Start building your migration capability now, while you have the luxury of time and low pressure. The next Black Friday, product launch, or growth spike will test your system's ability to evolve. Make sure you're ready.
Your users depend on your systems being available when they need them. By mastering zero-downtime migration strategies, you're not just solving a technical challenge - you're fulfilling that fundamental responsibility.
The database migration challenge that seemed daunting at the start of this article should now feel manageable, even exciting. The question isn't whether you can execute a zero-downtime migration - it's when you'll start building the capability to do it excellently.
Next week: "Polyglot Persistence: Using Multiple Database Types" - How Uber manages 15+ different database technologies in a single application architecture.
Previous: "Database Caching Layers: From Memory to Disk" - The multi-tier caching strategies that let Discord handle 5 billion messages per day.
Did this help you think differently about database migrations? Reply and share your biggest takeaway - I read every response and often feature insights in future articles.
Know someone wrestling with database scaling challenges? Forward this article. Migration capability is one of those skills that separates senior engineers from the rest.