
Database Replication: Master-Slave vs. Multi-Master
Issue# 26 of System Design Interview Roadmap: Part II Data Storage
Upgrade to Lifetime Access subscription & Get one year free subscription to Hands on course portal : “systemdrd.com” that offers wide variety of hands on courses on covering multiple high demanding technologies
The silent guardians of your data's availability and durability
Last week, I was troubleshooting a production incident at 3 AM when our primary database server unexpectedly went down. What saved us wasn't heroic coding—it was the replication architecture we'd carefully designed months before. Within seconds, a slave node seamlessly promoted itself to master, and most users never noticed the hiccup. This experience reminded me why database replication isn't just theoretical—it's the difference between a minor incident and a career-defining disaster.
The Hidden Power of Database Replication
Database replication creates and maintains copies of your data across multiple database instances. But replication isn't just about having backups—it's about ensuring data accessibility, load distribution, and failure resilience at scale.
At its core, database replication needs to answer two critical questions:
How do we propagate changes across database instances?
How do we handle conflicts when they inevitably arise?
Let's explore the two dominant replication models that solve these problems in fundamentally different ways.
Master-Slave Replication: The Reliable Workhorse
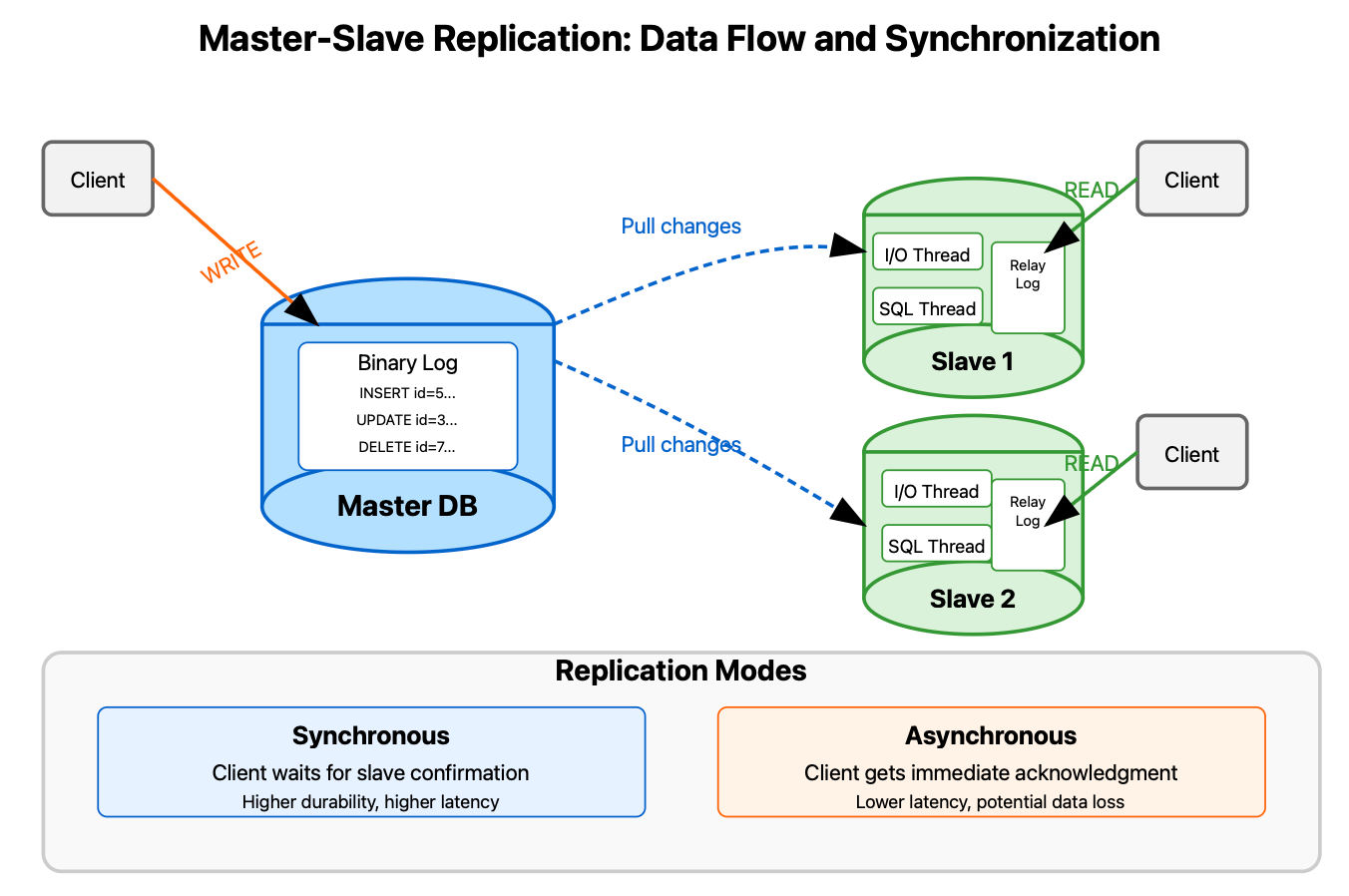
Master-slave replication (also called primary-replica) establishes a clear hierarchy: one primary database (the master) processes all write operations, while multiple replicas (slaves) synchronize with it to serve read operations.
How It Actually Works
When a client writes data to the master:
The master records the change in its binary log (binlog)
The slave's I/O thread continuously pulls these changes
The slave's SQL thread applies changes to its local dataset
The slave acknowledges successful replication
The magic happens in how this data propagates—either synchronously or asynchronously:
Synchronous replication waits for at least one slave to confirm the write before acknowledging success to the client. This ensures data durability but increases latency.
Asynchronous replication acknowledges the client immediately after the master records the change, without waiting for slaves. This improves performance but risks data loss if the master fails before replication completes.
Real-World Implementation: LinkedIn's Databus
LinkedIn built Databus, a change-data-capture system that powers their master-slave replication at massive scale. Databus captures changes from the master's transaction logs and reliably delivers them to thousands of slave databases and caching systems with minimal latency. This allows LinkedIn to handle over 1 million write operations per second while maintaining read performance through strategic slave placement.
What makes Databus truly innovative is its "bootstrapping" capability—the ability to quickly bring new slaves online by transferring only the necessary delta from existing replicas rather than copying the entire dataset from the master.
Multi-Master Replication: The Distributed Frontier
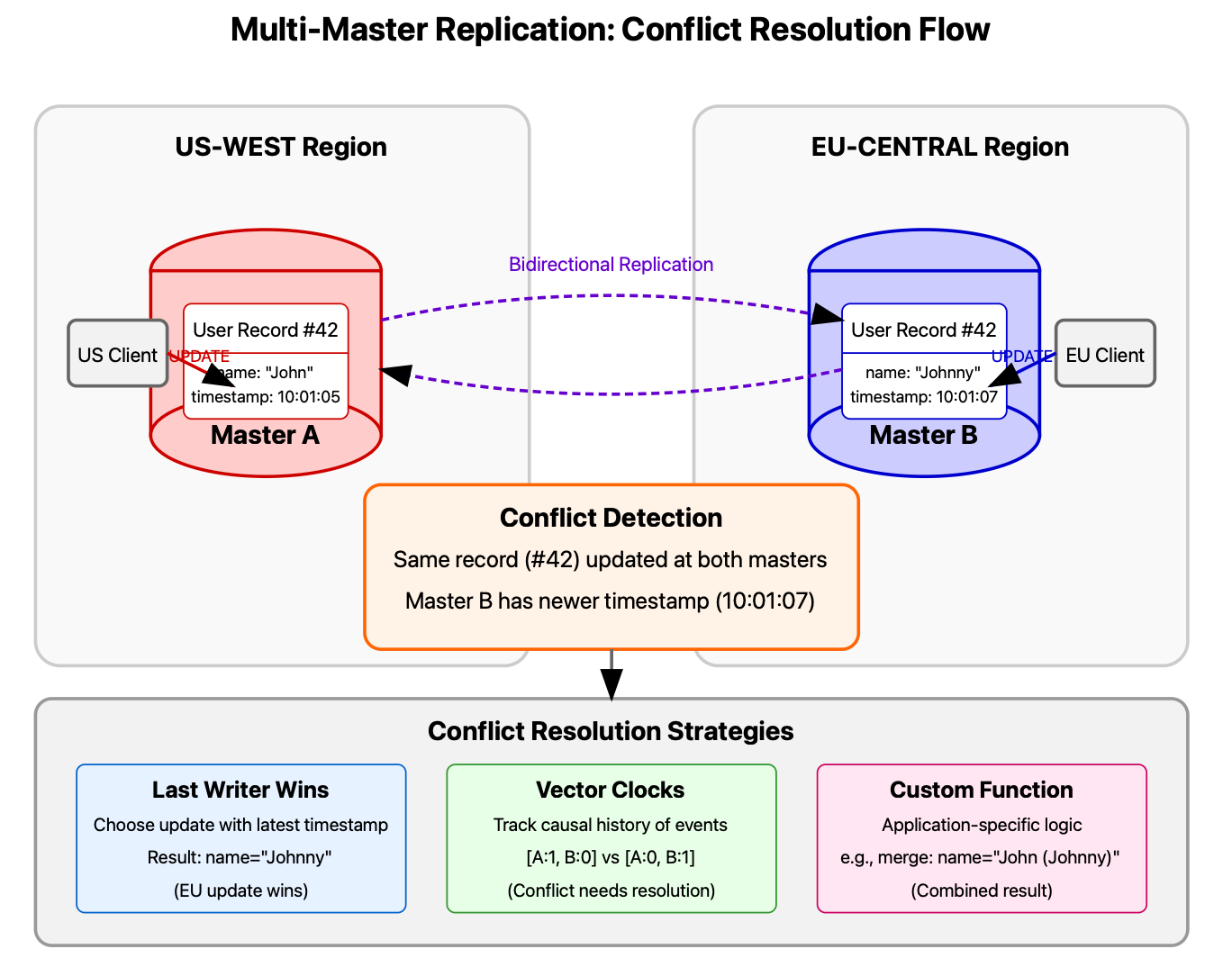
Unlike the hierarchical master-slave model, multi-master replication allows writes to occur on any database node. This dramatically improves write availability and geographical distribution but introduces complex conflict resolution challenges.
The Conflict Challenge
When two users simultaneously update the same data on different masters, you face a fundamental conflict. Multi-master systems typically handle this through:
Timestamp-based resolution: The update with the latest timestamp wins Vector clocks: Mathematical structures that track causal relationships between events Custom conflict resolution functions: Application-specific logic that determines which update prevails
Real-World Application: Amazon DynamoDB
Amazon's DynamoDB uses multi-master replication across multiple regions with a conflict resolution mechanism called "last writer wins." While conceptually simple (the most recent write takes precedence), the implementation requires sophisticated vector clock management to handle clock skew across global data centers.
What's particularly interesting is how DynamoDB propagates updates through a combination of synchronous and asynchronous replication: writes to the local region complete synchronously, while cross-region replication happens asynchronously in the background, creating a hybrid model that balances consistency and performance.
Choosing Your Replication Strategy
Your choice between master-slave and multi-master replication depends on several factors:
Choose Master-Slave when:
Strong consistency is critical
Your workload is read-heavy
Your application can direct writes to a single point
You need simpler failure recovery procedures
Choose Multi-Master when:
Write availability is paramount
Your system is geographically distributed
You can tolerate eventual consistency
You have mechanisms to resolve conflicts
Practical Implementation Exercise
Let's implement a basic master-slave replication monitor in Python that tracks the replication lag between a master and its slaves:
Source file : replication.py
This monitoring tool provides early warning when replication lag exceeds acceptable thresholds—often the first sign of brewing trouble in your database infrastructure.
Remember: replication is not just a feature but a fundamental architectural decision that shapes your entire system's resilience, scalability, and performance profile. Choose wisely, monitor diligently, and sleep better knowing your data persists even when hardware inevitably fails.