Database Schema Migrations with Zero Downtime: The Expand-Contract Pattern
The Problem at 3 AM
Your team lands a contract requiring you to split a
full_namecolumn intofirst_nameandlast_nameacross 200 million rows. The naive approach:ALTER TABLE users DROP COLUMN full_name, ADD COLUMN first_name VARCHAR, ADD COLUMN last_name VARCHAR. You run it during “low traffic” at 2 AM. Postgres acquires anACCESS EXCLUSIVElock. For 47 minutes, your entire application is offline because every query touchingusersis blocked. The on-call engineer gets paged. The customer escalates. You revert, losing four hours of data. This is a schema migration war story that has happened at every company operating relational databases at scale.
The Expand-Contract pattern eliminates this failure mode entirely.
Core Concept: Expand, Then Contract
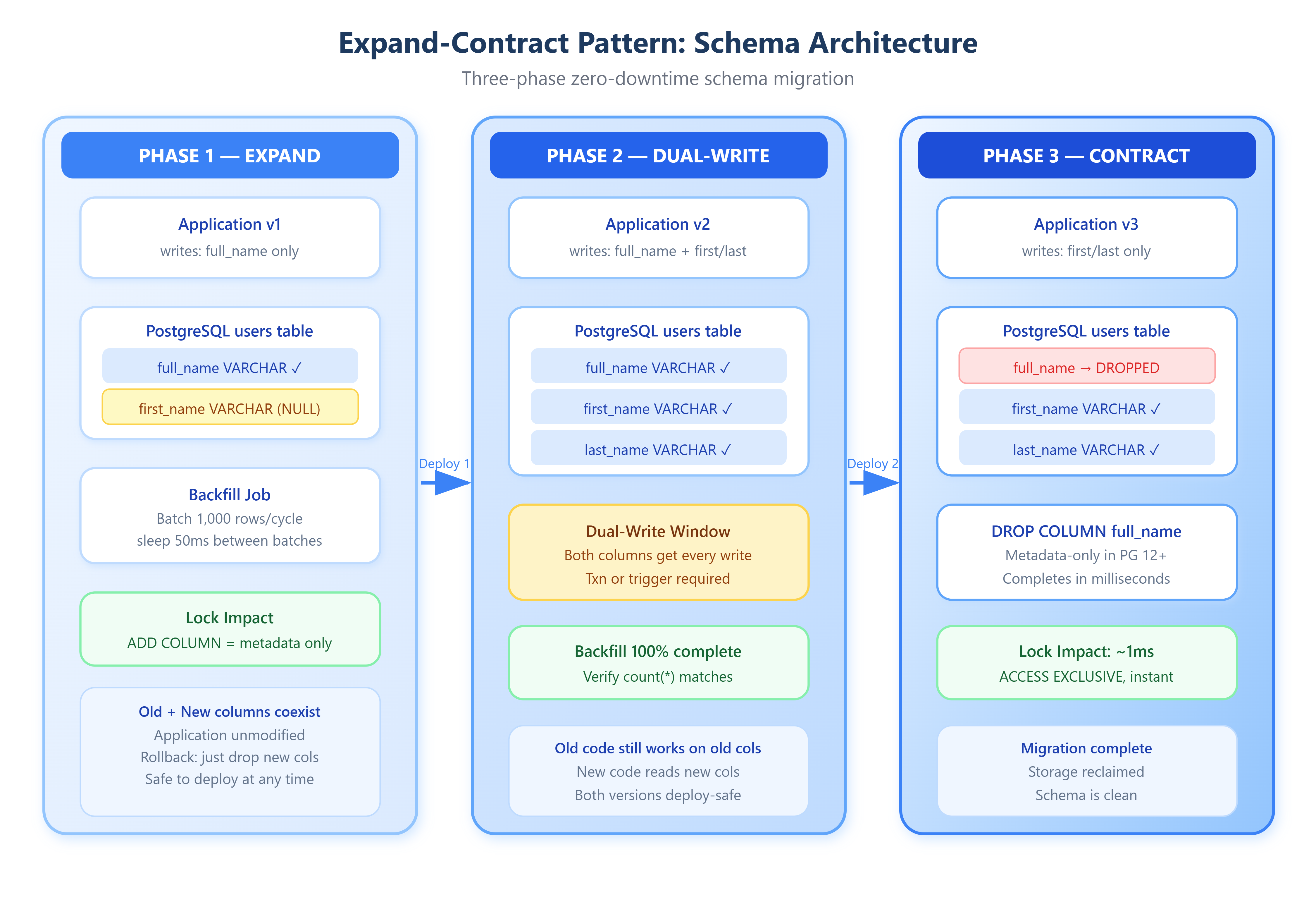
The pattern decomposes a breaking schema change into three discrete deployment phases, each independently reversible and safe to ship independently.
Phase 1: Expand
Add new columns/tables alongside the existing ones. Never drop, never rename—only add. The new schema coexists with the old. The application code is not yet modified to write to the new columns; only background jobs or triggers begin populating them.
Phase 2: Migrate
Backfill historical data into the new columns in batches (typically 1,000–10,000 rows per batch with a deliberate sleep between batches to avoid I/O saturation). Once backfill completes, deploy application code that writes to both old and new columns simultaneously. This dual-write phase is critical: any new writes land in both locations, ensuring the new schema never falls behind.
Phase 3: Contract
After verifying that the new columns are fully populated and the new code has been live long enough to drain in-flight requests from the old code path, drop the old column. This ALTER TABLE is now a metadata-only operation in most modern databases—it completes in milliseconds regardless of table size.