
This is the question that gets butchered more than any other in system design prep. Most resources hand you a 5-minute toy answer suitable for a phone screen and call it done. In a real onsite, this question runs 50 to 60 minutes, and the interviewer is using it to probe at least four distinct skills: capacity reasoning, ID generation under distributed constraints, caching strategy, and your awareness of failure modes. Miss two of the four and you fail the round, regardless of how clean your boxes-and-arrows came out.
This walkthrough is the senior version. If you are prepping for L4 / mid-level the bar is lower — you can stop after Step 5. For L5 / senior and L6 / staff, the deep dives are where the round is won or lost.
The Question
“Design a URL shortener service like bit.ly. The service takes a long URL and returns a shorter alias that, when accessed, redirects to the original.”
This question turns up in essentially every system design loop — Amazon, Google, Twitter / X, Reddit, Stripe, Pinterest, and most Series B+ startups doing senior-and-up hires. It is popular because it is a bounded problem with multiple defensible architectures, which makes it a good lens on how you think rather than what you have memorized.
Step 1 — Clarify Before You Draw
Three questions before you draw a single box. Ask these out loud, even if you think you can guess the answer. Spending ninety seconds here is what produces the senior signal.
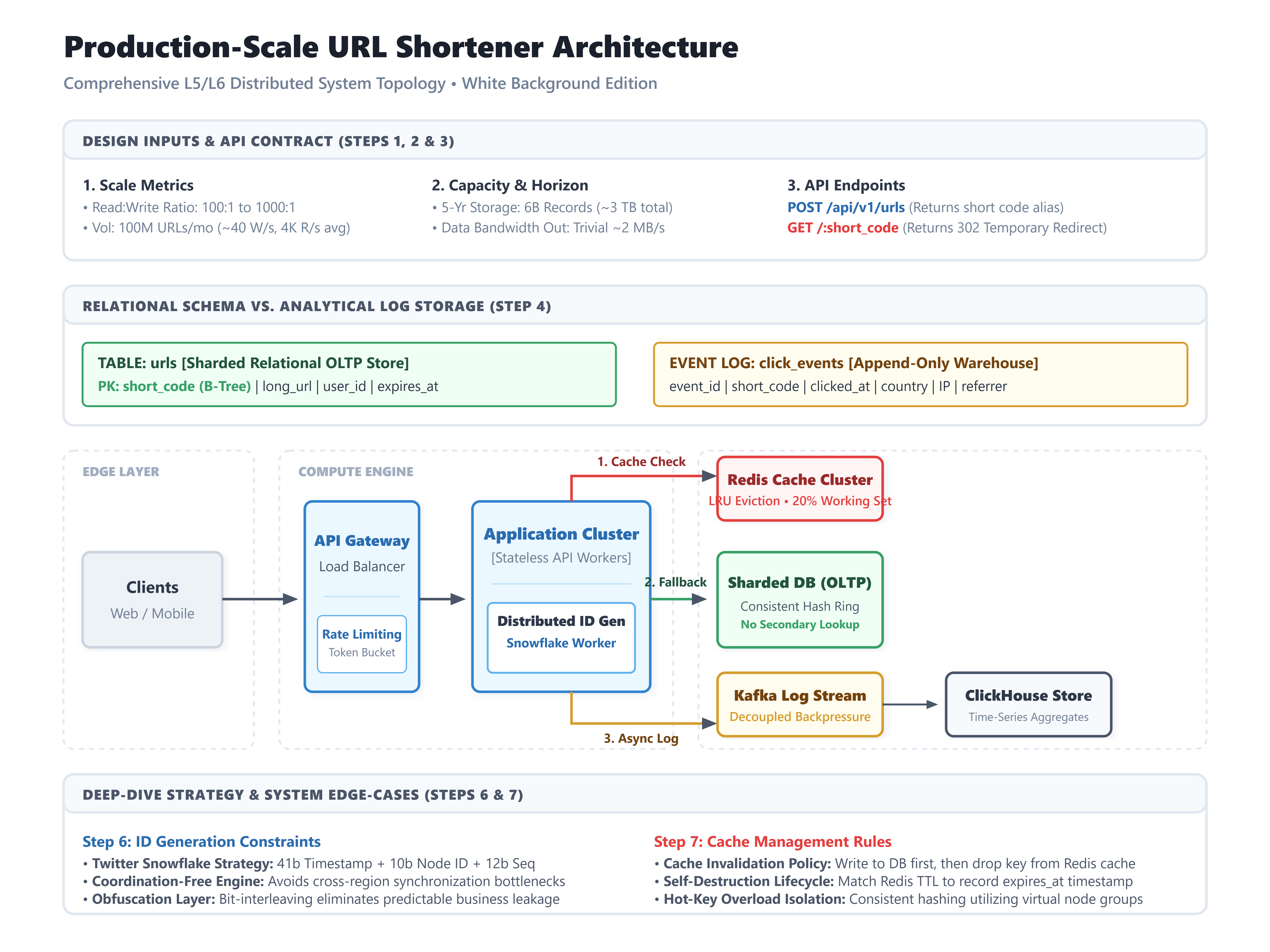
1. Read-to-write ratio? The almost-universal answer is somewhere between 100:1 and 1000:1. Most short URLs get clicked many more times than they get created. This number drives every caching decision later in the round, so you need it pinned down.
2. Custom short codes allowed, or system-generated only? This question splits the design in half. System-generated only: you can use auto-incrementing IDs and have no collision problem at all. Custom codes allowed: you have a uniqueness check on every write, plus a hot-key problem because everyone wants short, memorable aliases like /sale or /promo.
3. Analytics required? Click counts, geographic data, referrer tracking? If yes, this is no longer a key-value problem. It becomes a key-value problem plus an event pipeline plus an aggregation system. The interviewer is testing whether you spot that the analytics requirement reshapes the architecture.
A senior candidate writes the answers to these three questions on the whiteboard. A junior candidate skips this step, designs for the wrong assumptions, and has to restart twenty minutes in.
Step 2 — Estimate
Pick numbers that justify your architecture. Imprecision is fine; sloppiness is not.
Working assumptions for the rest of this walkthrough:
100M new URLs created per month, which gives roughly 40 writes per second on average, with peaks 5 to 10x higher
100:1 read-to-write ratio, giving roughly 4,000 reads per second on average, with peaks above 40K
5-year retention horizon
Average record size: 100 bytes for the long URL, 7 bytes for the short code, plus metadata — call it 500 bytes per record
Storage: 100M × 12 × 5 = 6 billion URLs over five years. At 500 bytes per record that is 3 TB. This fits comfortably on a single sharded relational database. You do not need anything exotic.
Bandwidth: 4,000 reads per second × 500 bytes is about 2 MB/s of read traffic. Trivial.
The estimation is not decoration. You will reference these numbers four more times before the round ends — when you justify caching, when you justify sharding, when the interviewer asks “what if we 100x’d the traffic?” Every later trade-off comes back to these inputs.
