Designing a Chat System: Storing History, Read Receipts, and Online Status (Presence)
The Three-Second Problem
You send a message in a group chat with 47 people. Within three seconds, you need to know: did it save? Who saw it? Who’s actually online right now? That three-second window contains six distinct database writes, 47 WebSocket notifications, and a presence check across three data centers. Miss any piece, and users lose trust in your platform. This is why WhatsApp processes over 100 billion messages daily while maintaining sub-second delivery guarantees—every architectural decision cascades into user perception of reliability.
The Three Pillars of Chat Architecture
Building a chat system requires solving three interconnected challenges simultaneously: durable message storage, accurate read receipt tracking, and real-time presence management. Each pillar has failure modes that aren’t immediately obvious.
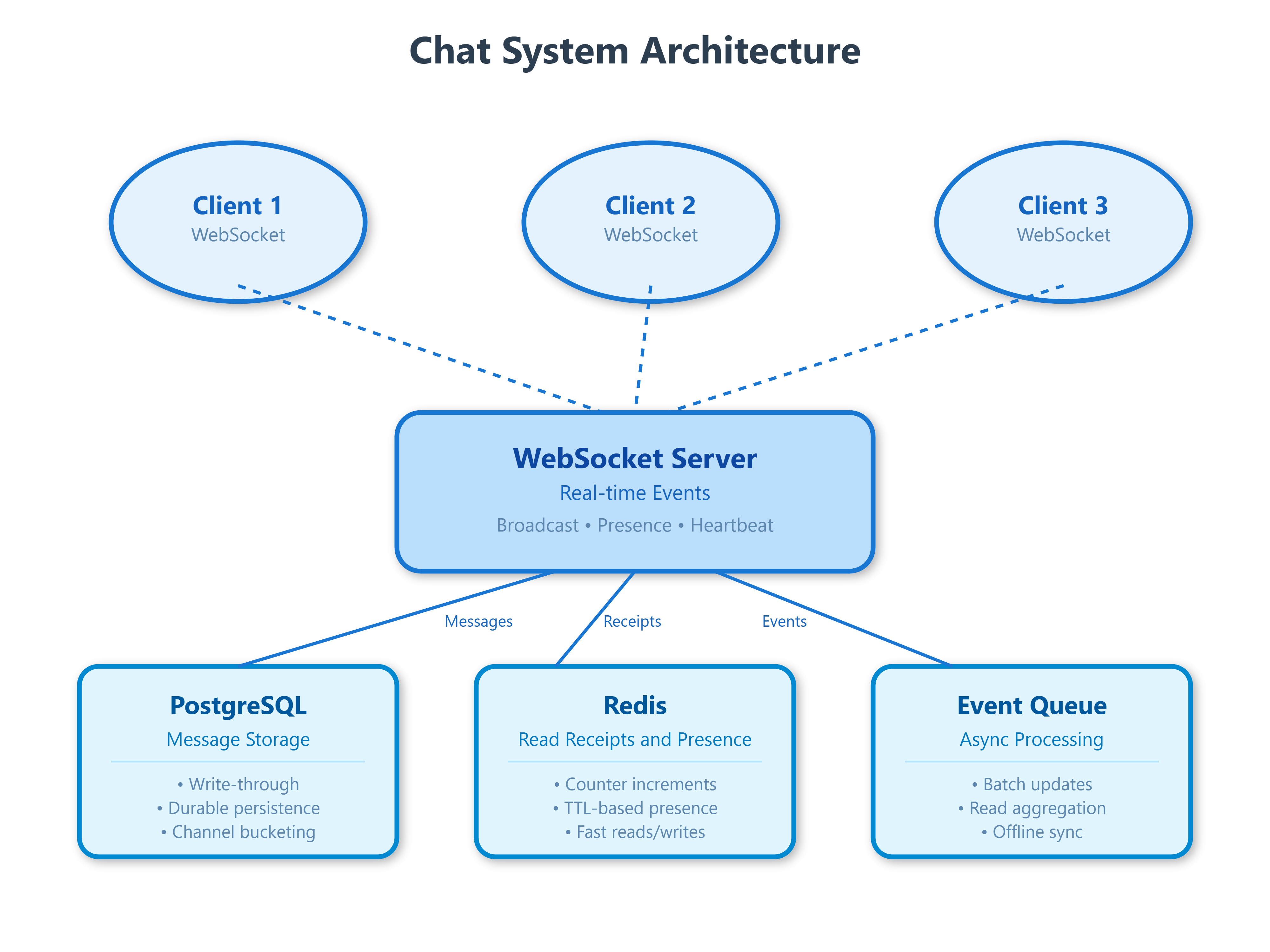
Message Storage: Write-Through vs Write-Behind
Most chat systems face a critical decision: do you confirm message delivery after writing to the database (write-through) or after acknowledging receipt in memory (write-behind)? WhatsApp uses write-through—your message doesn’t show a checkmark until it’s persisted to their distributed storage. This adds 50-100ms of latency but guarantees durability. Slack, conversely, uses write-behind with append-only logs, acknowledging messages immediately then asynchronously persisting to their data warehouse. The trade-off: Slack feels faster but has a small window where messages could be lost in a catastrophic failure.
The storage schema matters enormously at scale. Discord stores messages in ScyllaDB using a compound partition key: (channel_id, bucket) where bucket represents a 10-day window. This prevents hotspot partitions when popular channels receive thousands of messages per minute. Without bucketing, all writes to a single channel would hit the same partition, creating a bottleneck. They learned this the hard way when a server with 1.5 million users experienced 90-second message delays because all messages shared a single partition key.
Read Receipts: The Phantom Update Problem
Read receipts seem simple—just update a timestamp when someone reads a message, right? Wrong. At scale, you face the “phantom update problem”: if 1,000 people are in a channel and one person sends a message, you potentially need to track 1,000 read states. If those users read the message within the same minute, you’re writing 1,000 database updates in rapid succession.
Telegram solves this with a distributed counter architecture. Each read receipt increments a Redis counter, and every 10 seconds, a background job flushes aggregated counts to PostgreSQL. The sender sees “1,847 views” instead of individual timestamps, drastically reducing write amplification. For one-on-one chats where precision matters, they use a hybrid approach: instant updates for direct messages, aggregated counts for groups.
The critical edge case: what happens when a user goes offline mid-read? Signal handles this by storing “last_read_message_id” per conversation. When you reconnect, the client sends a batch read receipt for all messages since that ID. This prevents the “unread badge flickering” problem where offline periods cause read states to become inconsistent.