
Designing for Failure: Mastering Timeouts, Retries, and Circuit Breakers
Last month, a payment processor I consulted with experienced a 4-hour outage that cost them $2.3M in revenue. The root cause? A single overloaded service without proper timeout handling triggered cascading failures across their system. It's a story I've seen repeated countless times—sophisticated systems brought to their knees not by complex bugs, but by missing or misconfigured failure handling mechanisms.
Today, we'll explore three critical patterns that form the foundation of resilient distributed systems: timeouts, retries, and circuit breakers. These aren't just interview topics; they're the difference between a system that gracefully weathers storms and one that collapses under pressure.
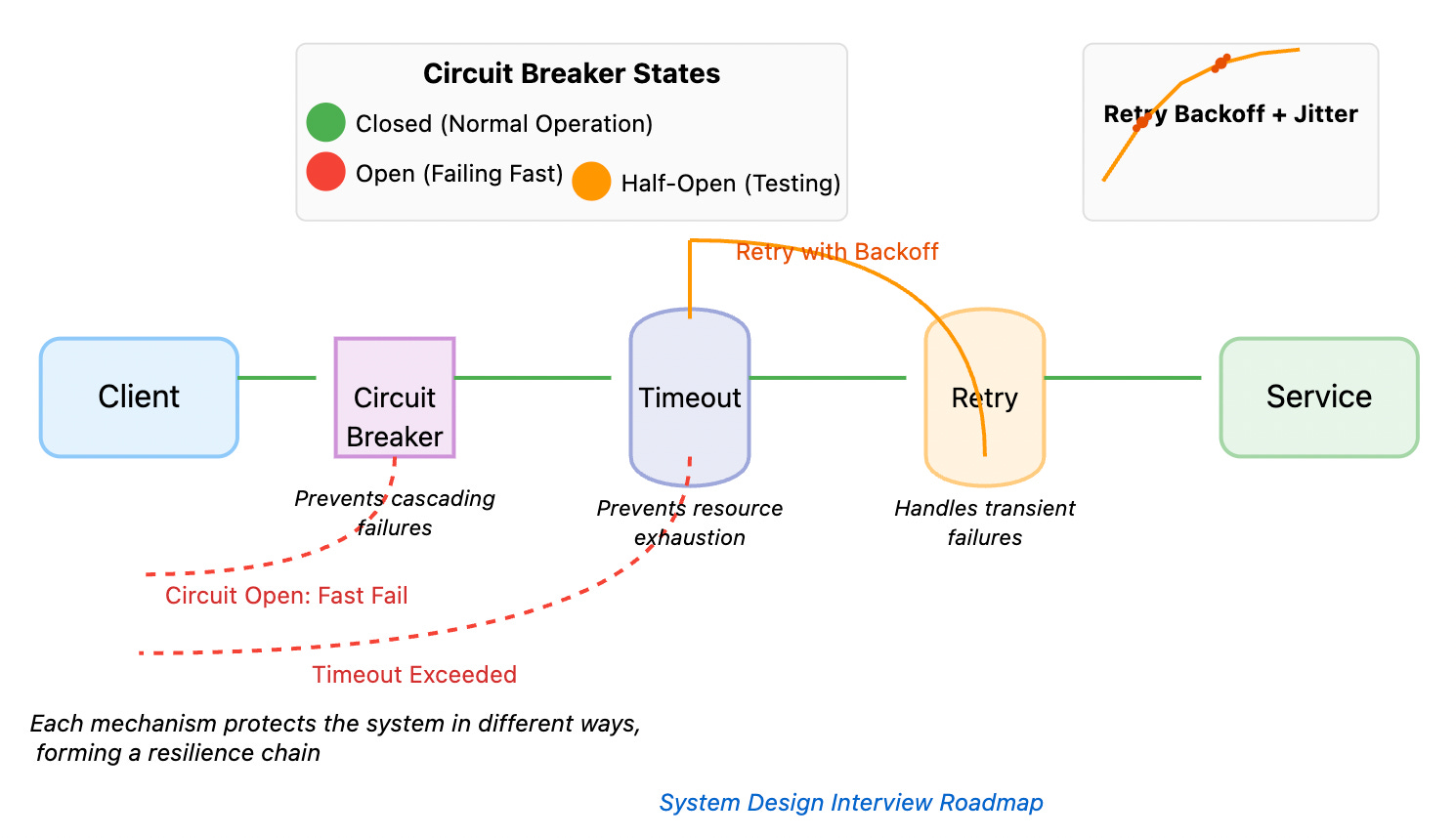
Timeouts: Your First Line of Defense
A timeout is essentially a promise to yourself: "I will not wait forever." While conceptually simple, timeouts are surprisingly nuanced in practice.
Keep reading with a 7-day free trial
Subscribe to System Design Interview Roadmap to keep reading this post and get 7 days of free access to the full post archives.