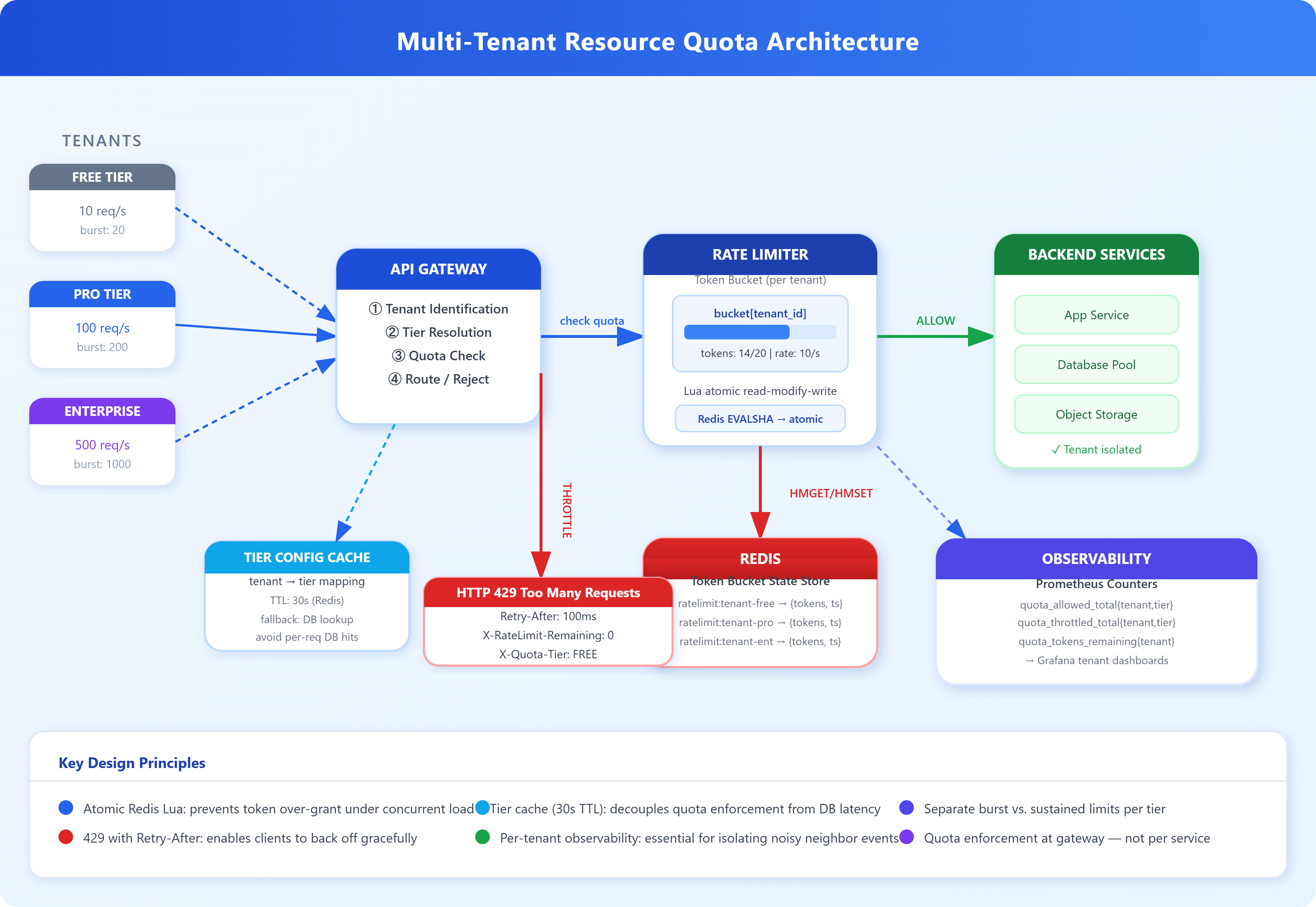
Designing for "Noisy Neighbors" — Multi-Tenant Resource Limits and Quotas
The Problem That Breaks Trust at Scale
Picture a SaaS platform where one customer runs a poorly-written batch job at 2 AM — hammering your API at 50,000 requests per minute. By 2:03 AM, every other customer’s p99 latency has tripled. Your database connection pool is exhausted. Smaller tenants are getting timeouts they can’t explain. This is the noisy neighbor problem, and it’s one of the most common causes of silent SLA breaches in multi-tenant systems.
The challenge isn’t just rate limiting. It’s designing a fair, enforceable, tier-aware quota system that isolates tenant behavior without introducing new failure modes.
Core Concept: Resource Quotas in Multi-Tenant Systems
Multi-tenancy means multiple customers share the same physical infrastructure — compute, memory, network bandwidth, database connections. Isolation between tenants is mostly logical, not physical. This is economically necessary (dedicated infrastructure per tenant is prohibitively expensive at scale), but it creates coupling: what one tenant does affects what others experience.
Resource quotas are the enforcement layer that converts logical isolation into predictable guarantees. They operate across multiple resource dimensions simultaneously:
Request rate (requests/second): The most visible dimension. Enforced via token bucket or leaky bucket at the API gateway.
Concurrency (parallel connections): How many simultaneous in-flight requests a tenant can hold. Critical for preventing connection pool exhaustion.
Compute quotas (CPU/memory): Enforced at the container level via cgroups. Kubernetes ResourceQuotas translate to cgroup limits on pods.
Bandwidth / egress: How much data a tenant can read or write per unit time. Prevents storage-backed services from being starved by bulk exporters.
Storage quota: Total bytes a tenant can persist — enforced at the object store or database partition level.
The token bucket algorithm is the dominant mechanism for request-rate enforcement. Each tenant has a bucket with a capacity (burst limit) that refills at a fixed rate (sustained limit). Each request consumes one token. When the bucket is empty, requests are rejected with HTTP 429. This allows legitimate bursts — a tenant can use accumulated tokens for a spike — while enforcing a sustained rate ceiling. The implementation is almost always in Redis: a Lua script atomically reads the bucket state, calculates tokens added since the last refill, and either grants or denies the request.
Non-obvious behavior: token buckets are vulnerable to synchronization storms. If a tenant gets throttled and all their retry logic backs off for exactly the same duration, they’ll re-hit the limit simultaneously when the backoff expires. Jitter on the retry delay (randomized exponential backoff) breaks this up. This is not hypothetical — Stripe’s API clients include jitter precisely because they’ve observed the pattern in production.
Weighted fair queuing (WFQ) goes further than per-tenant limits. Instead of hard rejection, WFQ assigns each tenant a weight and processes requests proportionally. A free-tier tenant gets 1/10th the processing share of an enterprise tenant, but neither is completely starved. This model trades determinism for fairness — you can no longer guarantee a specific rate, but you eliminate the cliff edge where small tenants become entirely blocked by large ones.
Burst allowances and sustained limits are different numbers and must be configured separately. A misconfigured system that sets burst = sustained rate causes legitimate traffic spikes to fail (webhook delivery, scheduled report generation). A system that sets burst too high defeats the protection. The right burst-to-sustained ratio depends on traffic profile — typically 2–10x for interactive applications, narrower for background job APIs.