Designing Real-Time Leaderboards: Redis Sorted Sets and Architecture Patterns
When Every Millisecond Counts on the Scoreboard
You’re playing a mobile game with millions of concurrent players. You land a perfect combo, your score jumps 50,000 points, and within 200 milliseconds, you see yourself climb from rank #4,832 to #2,156 on the global leaderboard. No loading spinners. No “refresh to see updated rankings.” Just instant feedback that makes you want to beat one more level.
Behind that seamless experience lies one of distributed systems’ most elegant solutions: Redis Sorted Sets. They power real-time leaderboards at gaming giants, fitness apps tracking daily steps, trading platforms showing top performers, and social networks ranking trending content. The architecture seems simple—until you’re handling 50,000 score updates per second across 100 million players.
The Mechanics of Instant Rankings
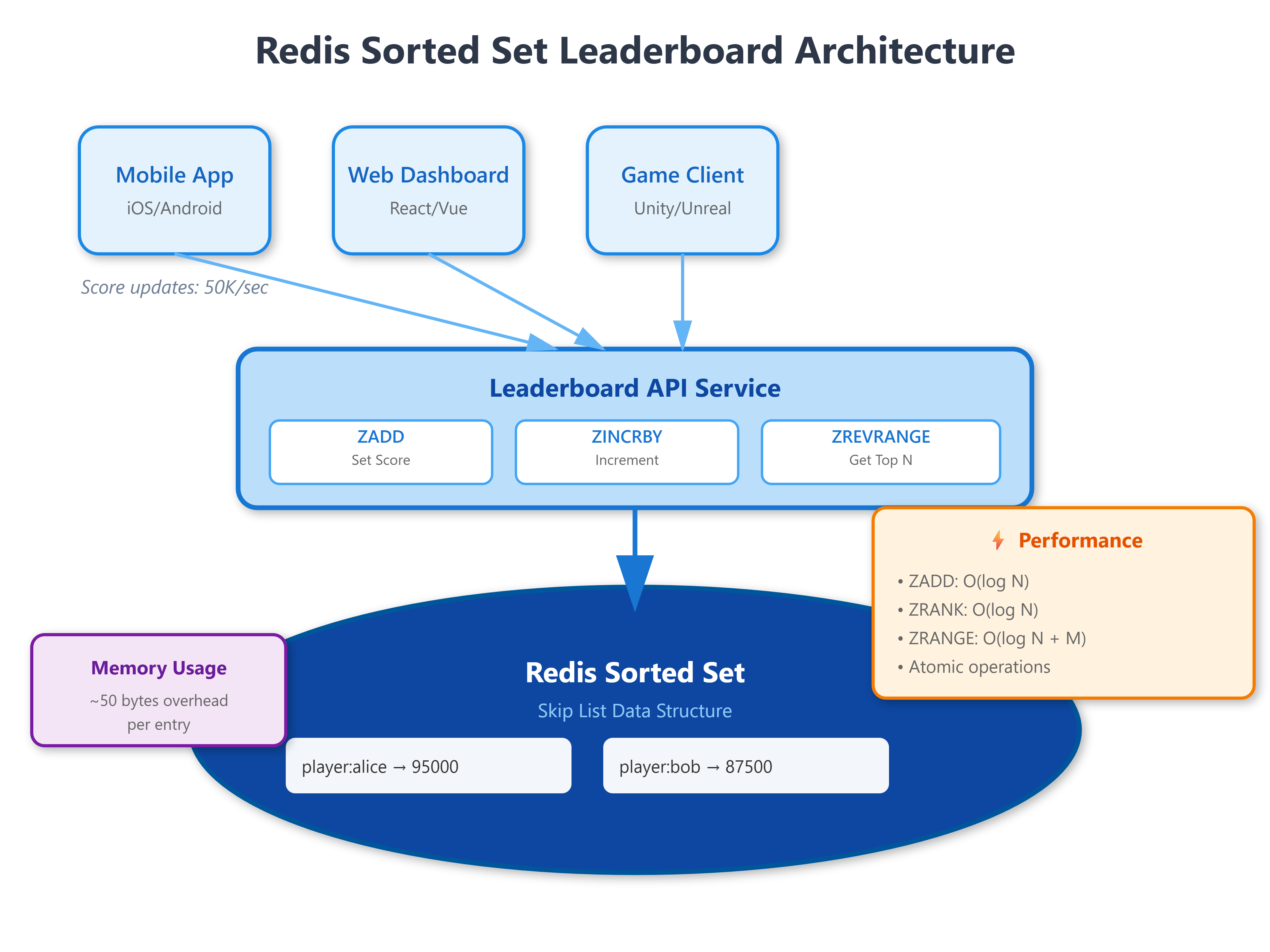
Redis Sorted Sets are fundamentally different from regular sets or lists. Each member has both a value (the player ID) and a score (their points), stored in a skip list data structure that maintains sorted order automatically. When you add or update a score, Redis repositions that member in O(log N) time—meaning whether you have 1,000 or 10 million entries, updates remain blazingly fast.
The genius is in the API design.
ZADD leaderboard 95000 player:aliceatomically updates Alice’s score to 95,000 and adjusts her rank.ZREVRANK leaderboard player:alicereturns her position in constant time.ZREVRANGE leaderboard 0 99 WITHSCORESfetches the top 100 players with their scores in a single round trip. No complex queries, no table scans, no sorting in application code.
What makes this architecture production-ready is atomicity. When millions of updates hit simultaneously, Redis processes each operation sequentially through its single-threaded event loop. Two players scoring simultaneously never corrupt the leaderboard state. This eliminates entire classes of race conditions that plague custom implementations using databases with SELECT-then-UPDATE patterns.
The skip list structure provides logarithmic performance for insertions and rank lookups, but here’s the non-obvious part: range queries are linear in the number of elements returned, not the total set size. Fetching the top 10 players is O(log N + 10) whether you have 100 or 100 million total players. This asymmetric performance profile is why leaderboards feel instant even at massive scale.