
Designing Systems for Global Scale: Airbnb Case Study
Introduction
When Airbnb crossed 100 million bookings, their architecture faced a problem most engineers never encounter: guests searching for homes in Tokyo were hitting databases in California, taking 800ms just for network round-trips. The solution wasn’t throwing more servers at the problem—it required fundamentally rethinking how data lives across continents.
The Geographic Sharding Reality
Airbnb doesn’t replicate everything everywhere. Instead, they partition listings by geographic regions with a twist: each listing exists in exactly one primary region, but availability data replicates globally. A Tokyo apartment’s details live in Asia-Pacific databases, but its calendar syncs to all regions within 50ms. This asymmetric approach cuts storage costs by 70% while keeping search fast.
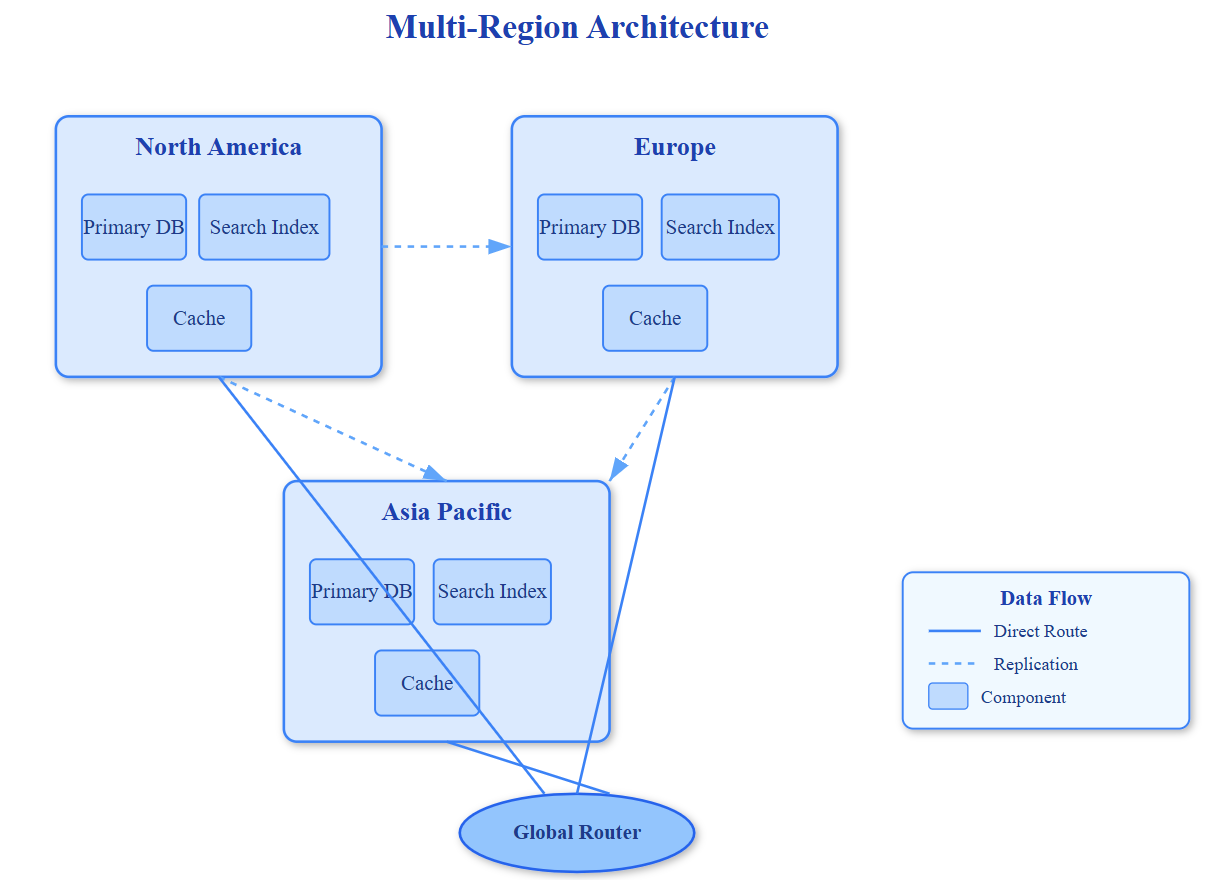
The non-obvious insight? Search queries don’t need real-time data. When you search “Paris apartments,” you’re seeing availability from 2 minutes ago—and you don’t notice. Airbnb’s search indexes refresh every 90 seconds, decoupling read-heavy search from write-heavy bookings. This temporal decoupling handles 5 million searches per hour without touching primary databases.
The Double-Booking Problem Nobody Talks About
Here’s what breaks at global scale: two guests in different continents book the same apartment simultaneously. Network latency means both see “available,” both click “reserve,” and both transactions start. Traditional distributed locks fail here—by the time Tokyo’s lock request reaches San Francisco, New York’s booking already committed.
Airbnb solved this with optimistic locking combined with regional priority. Each booking gets a 60-second hold with a timestamp. If conflicts occur, the transaction with the earliest timestamp wins, others get gracefully rejected with alternative recommendations already loaded. The key: they pre-fetch alternatives before showing confirmation, so failures feel like guided choices, not errors.
