Distributed Tracing Sampling Strategies: Balancing Visibility vs. Storage Costs
Introduction
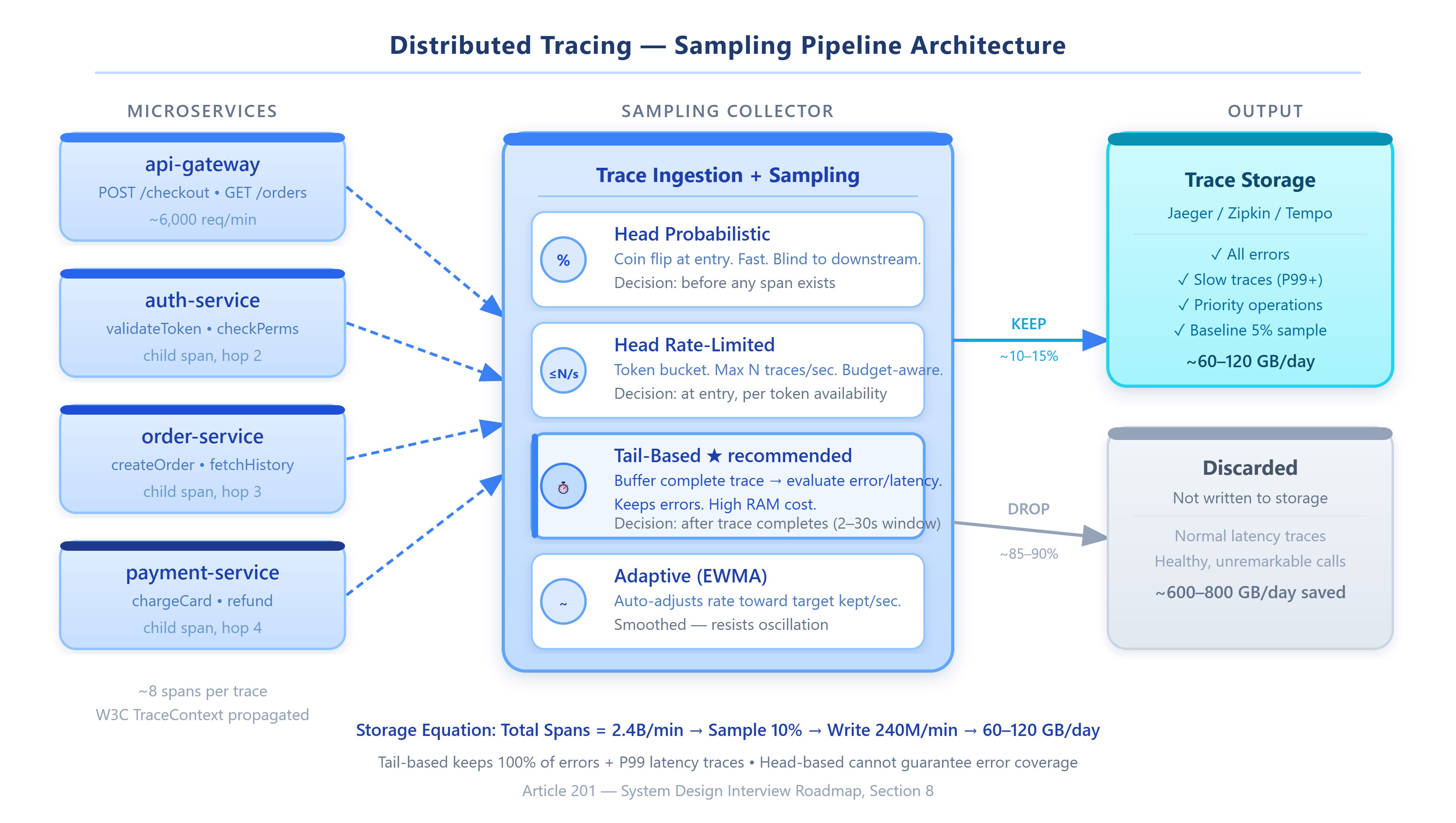
At 10 million requests per minute, storing a complete trace for every request would flood your Jaeger backend with roughly 400–600 GB of span data per hour, depending on service depth. Nobody does that. You sample. But sampling is not just “keep 1% of traces and move on.” The decision of which traces to keep, when to make that decision, and how to adapt under load separates systems that debug in minutes from teams that fly blind during incidents.
What Sampling Actually Does
A distributed trace is a tree of spans — each span recording one unit of work (an RPC call, a database query, a cache lookup) with timestamps, metadata, and status codes. In a system with 30 microservices and 8-hop average request depth, a single user request generates ~240 spans. At 10M RPM, that’s 2.4 billion spans per minute.
Sampling is the process of deciding which trace trees to persist and which to discard. Every sampling strategy must answer two questions: when does the decision happen, and what information is available at decision time?
Head-Based Sampling
The sampling decision is made at the trace’s entry point — before any downstream spans exist. The API gateway or load balancer rolls a coin: 10% probability, keep the trace ID; 90%, mark it discarded. All downstream services check the trace context header and skip recording if the trace is marked discarded.
Mechanism: The trace context (W3C TraceContext spec, or Jaeger’s uber-trace-id) carries a sampled flag. Downstream services read this flag and skip span creation entirely, saving both CPU and network overhead.
The fatal flaw: You make the keep/drop decision before you know whether anything interesting happened. A payment that timed out at step 7 of 8 — dropped at step 0 because the coin flip went against it. A 4-second database stall — dropped. An auth service returning 403 for a premium user — dropped. Head-based sampling is statistically unbiased but operationally blind.
Tail-Based Sampling
The decision is deferred until the trace is complete. All spans from all services flow into a central buffer. After a configurable window (typically 2–30 seconds), a tail-sampling processor evaluates the complete trace tree and decides: does this trace contain an error? Was end-to-end latency above the P99 threshold? Did it hit a rare code path?
Mechanism: The buffer stores spans in-memory, grouped by trace ID. When a trace is complete (all spans received, or the timeout fires), a set of rules runs: has_error OR latency > threshold OR service_count > N. Matching traces write to storage; non-matching traces are discarded.
The cost: You buffer everything before deciding. Memory scales with (RPS) × (avg trace duration) × (avg span size). At 10K RPS, 500ms average, 8 spans of 2KB each: 80MB/sec flowing through buffer RAM continuously. Manageable until your latency distribution has a long tail — a few 30-second traces balloon your buffer by orders of magnitude.
Adaptive (Dynamic) Sampling
The sampling rate adjusts automatically based on observed traffic volume, aiming for a target throughput: “keep 100 interesting traces per second regardless of incoming load.” When traffic is 1,000 RPS, sample at 10%. When traffic spikes to 50,000 RPS, drop to 0.2%.
Mechanism: A feedback controller tracks the actual kept-trace rate against the target. If the actual rate exceeds the target for N consecutive seconds, it tightens the sampling probability. If under target, it relaxes. Per-operation tracking (Jaeger’s adaptive sampler) sets different rates per endpoint — /health at 0.001%, /checkout at 5%.
Non-obvious failure: Adaptive samplers can oscillate. Traffic spikes → rate drops → fewer traces → pressure decreases → rate rises → traffic spikes again. Use exponential smoothing (EWMA) on the rate adjustment, not raw instantaneous values.