
Event Sourcing and CQRS: Advanced Patterns
Nothing teaches better than “Code in Action”.
Learn AI Agents : Join the AI agent revolution before your competition does.
Explore more hands-on courses on portal
Lifetime Access : 4 hands on courses + full portal with Pro Max offer → link
When Your Database Tells Stories Instead of States
At 2 AM, your payment system goes down. You restore from backup, but customers are reporting duplicate charges. The audit team needs to know exactly what happened at 11:47 PM when the bug was deployed. Your traditional CRUD database shows current balances, but the story of how money moved—the sequence of deposits, withdrawals, and transfers—is gone forever. Event Sourcing would have preserved every state transition as an immutable fact, letting you replay history and debug the impossible.
The Fundamental Shift: From State to Story
Traditional databases store the current state of your data. If a bank account has $1,000, that’s what you see.
Event Sourcing flips this model:
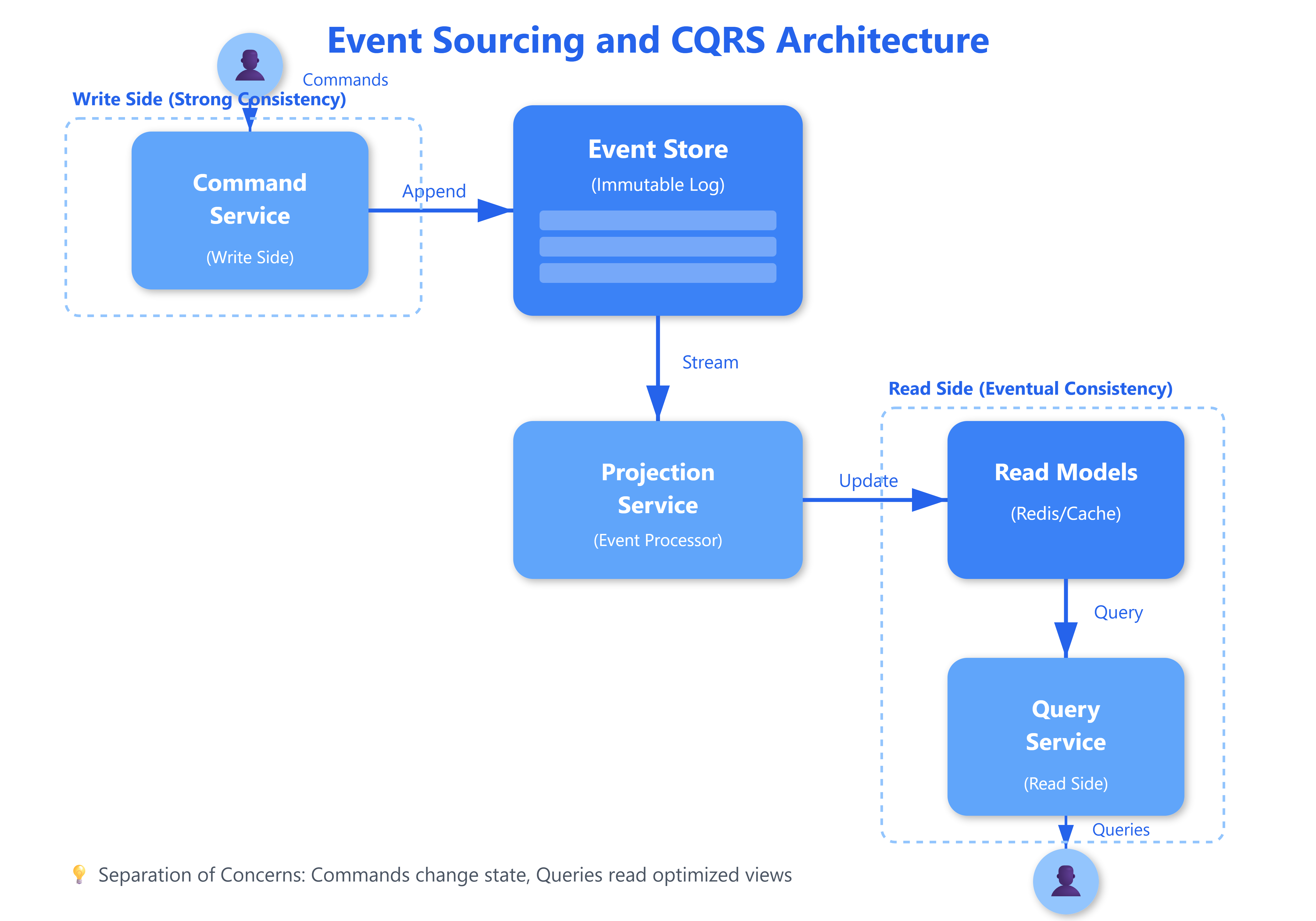
Instead of storing the current balance, you store every deposit, withdrawal, and transfer as an immutable event. The balance becomes a derived value—the sum of all events. This seems backwards until you realize that real-world systems are event-driven: money moves, orders ship, users click. Events are the truth; state is merely a cache.
CQRS (Command Query Responsibility Segregation) takes this further by splitting your system into two separate paths: commands that change state, and queries that read state. Commands append events to the event store. Queries read from optimized projections (read models) built from those events. This separation lets you optimize each side independently: the write side ensures consistency and business rule enforcement, while the read side prioritizes query performance with denormalized views.
The mechanism works through an event pipeline:
A command handler validates business rules and generates events. These events are persisted to an append-only event store with a global sequence number. Event processors asynchronously consume these events and update read models. Queries hit the read models directly, never touching the write side. This creates eventual consistency—read models lag behind writes by milliseconds to seconds, depending on processing speed.
The non-obvious behavior emerges at scale. When Netflix processes millions of viewing events per second, they can’t synchronously update every read model. Instead, they use Kafka to stream events to multiple consumers building specialized projections: one for recommendations, another for billing, a third for analytics. Each projection can fail and replay independently without affecting the write side. Traditional two-phase commit would collapse under this load.
The critical trade-off:
Eventual consistency means your read models might be stale. A user updates their profile, then immediately queries it—they might see old data. This requires careful UX design: show optimistic updates in the UI, use correlation IDs to track commands through the system, and provide feedback when operations are still processing. Amazon’s order confirmation pattern handles this elegantly: “Your order is being processed” acknowledges the command without claiming the read model is updated.
