
Eventual Consistency: When "Eventually" Is Good Enough
Article #27 of System Design Roadmap series, Part II: Data Storage
🔥 EXCLUSIVE WELCOME OFFER — 50% OFF
As a new subscriber, you get an exclusive 50% OFF on a paid subscription — giving you full access to “System Design in Action” with code demos that build a rock-solid foundation.
👉 Claim your 50% discount now: https://systemdr.systemdrd.com/7b6b3fb1 This is a limited-time offer — don’t let it slip!
🎁 YOUR FREE SUBSCRIBER GIFTS
Just for subscribing, you get a free copy of our System Design Fundamentals Book — the perfect companion to get started.
👉 Get your free book: https://systemdrd.com/ebooks/system-design-guide/
The Distributed Data Dilemma
Picture this: You're scrolling through your social media feed when you notice something strange. Your friend's new profile picture shows up in your feed, but when you visit their profile, you still see their old photo. A minute later, both are in sync. What just happened?
You've witnessed eventual consistency in action—a fundamental principle that powers many of the world's largest distributed systems. While immediate consistency feels intuitive (update once, see everywhere instantly), the reality of distributed computing makes this surprisingly difficult to achieve at scale.
Understanding Eventual Consistency
Eventual consistency is a consistency model that promises a beautifully simple guarantee: given enough time without new updates, all replicas of data will converge to the same state. The key word is "eventual"—we sacrifice immediate consistency for significant gains in availability and partition tolerance.
Unlike strong consistency models that block operations until all replicas confirm synchronization, eventual consistency allows systems to proceed with local updates and reconcile differences later. This trade-off forms the foundation of many modern distributed databases powering services you use daily.
Why Embrace "Eventually"?
Traditional relational databases trained us to expect ACID properties (Atomicity, Consistency, Isolation, Durability). So why would anyone willingly accept delayed consistency? The answer lies in the CAP theorem's uncomfortable truth: when a network partition occurs, you must choose between consistency and availability.
At massive scale, network partitions aren't theoretical—they're inevitable. Companies like Amazon discovered early that availability often trumps immediate consistency for many use cases. A brief delay in seeing a friend's profile picture is preferable to the entire social network becoming unavailable.
The business impact is significant. Studies suggest that even 100ms of latency can reduce conversion rates by 7%. By embracing eventual consistency where appropriate, companies can maintain responsiveness even under challenging network conditions.
The Hidden Complexity
The elegant simplicity of "updates will propagate eventually" hides considerable implementation complexity. Systems must track conflicting writes, resolve them intelligently, and handle the interim period where different replicas show different values—all without confusing users or corrupting data.
Let's explore how industry leaders tackle these challenges.
Eventual Consistency in a Distributed System
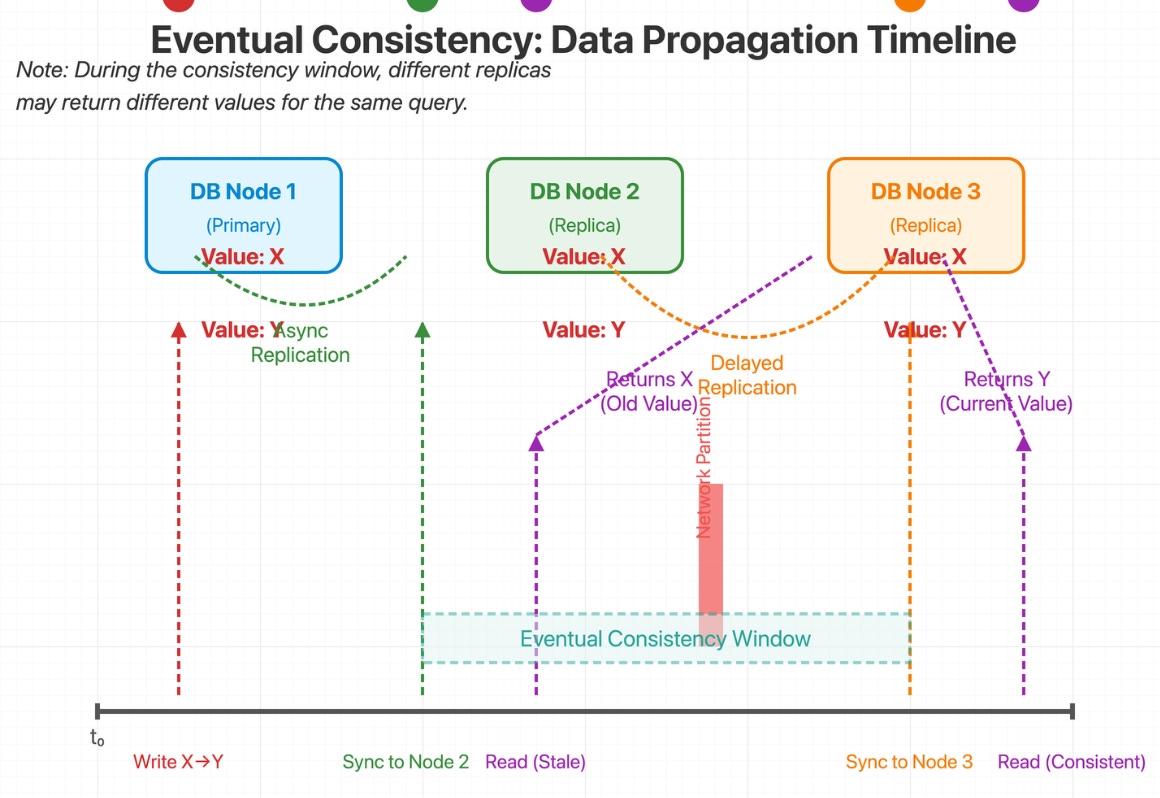
Real-World Implementation Strategies
1. Amazon DynamoDB: Tunable Consistency
Amazon's DynamoDB offers a masterclass in configurable consistency. Rather than dictating a one-size-fits-all approach, DynamoDB lets developers choose consistency levels on a per-request basis:
Eventually Consistent Reads: The default setting prioritizes low latency and high throughput by potentially serving slightly stale data.
Strongly Consistent Reads: When needed, applications can request the most up-to-date data at the cost of higher latency and lower throughput.
According to Amazon's white papers, this flexibility allows their internal teams to achieve 99.9999% availability while still offering strong consistency when business requirements demand it.
2. Cassandra: Tunable Consistency Quorums
Apache Cassandra, initially developed at Facebook and now powering systems at Netflix, Apple, and Instagram, uses quorum-based consistency levels. Writes succeed when a configurable number of replicas acknowledge receipt, offering a spectrum from "ONE" (fastest but least consistent) to "ALL" (strongest consistency but most vulnerable to unavailability).
What makes Cassandra particularly brilliant is its use of a gossip protocol for replica synchronization. Rather than relying on a central coordinator, nodes regularly exchange state information with random peers, spreading updates throughout the cluster similar to how rumors spread in social networks.
3. Conflict Resolution Strategies
When eventual consistency allows divergent values, systems need mechanisms to reconcile differences:
Last-Write-Wins: Simple but potentially lossy, timestamps determine the "winner"
Vector Clocks: Track causal relationships between updates
CRDTs (Conflict-free Replicated Data Types): Mathematical structures that guarantee convergence
Application-specific Resolution: Push conflict detection to application logic
Conflict Resolution with Vector Clocks

When to Choose Eventual Consistency
Not every use case requires immediate global consistency. Consider these scenarios:
Read-heavy workloads: Social media feeds, product catalogs, and content delivery benefit immensely from the scalability of eventual consistency with minimal user impact.
Analytics and metrics: When calculating approximations like "total page views" or "average response time," absolute precision is less critical than system availability.
Collaborative applications: Google Docs demonstrates how conflict resolution mechanisms can manage parallel updates without blocking users.
However, financial transactions, inventory management, and authentication systems typically require stronger consistency guarantees. The key is understanding your specific domain requirements.
Implementation Best Practices
Make Inconsistency Observable
Developers often struggle with eventual consistency because the "window of inconsistency" feels like a black box. Instrument your system to measure and alert on replication lag. Netflix open-sourced their Atlas monitoring system precisely to track these metrics across their massive infrastructure.
Design for Conflict Resolution
Rather than hoping conflicts never occur, assume they will and design accordingly:
Store multiple conflicting versions when detected
Implement domain-specific merge functions
Use monotonically increasing identifiers (e.g., UUIDs with embedded timestamps)
Consider CRDTs for automatic conflict resolution
Communicate Consistency Expectations
Set proper expectations with users. LinkedIn's "Your profile has been updated" messaging includes subtle cues when changes might not be immediately visible to others. This transparency prevents confusion and builds trust.
Implementing a Simple CRDT Counter : eventual.js

Building Resilient Applications on Eventually Consistent Systems
Rather than waiting for server confirmation, immediately reflect user actions in the UI while asynchronously propagating changes to the backend. If conflicts arise, reconcile them with minimal disruption. Instagram uses this approach for likes and comments—your interaction appears instantly while propagating through their infrastructure.
Idempotent Operations
Design operations that can be safely repeated without side effects. This allows for retry mechanisms without worrying about duplicate processing. For example, Stripe's payment API is deliberately idempotent—the same payment request with the same idempotency key won't charge a customer twice.
Read-Your-Writes Consistency
Even with eventual consistency, users expect to see their own changes immediately. Implement session affinity or client-side caching to ensure users always see at least their own most recent writes, even if others temporarily see older versions.
Real-World Case Study: Dynamo at Amazon
Amazon's original Dynamo paper (2007) transformed distributed database design by explicitly favoring availability over consistency. Their shopping cart system uses a "always writable" approach—even during network partitions, customers can add items to carts. If conflicts occur (e.g., items added on different replicas), the system preserves all items rather than arbitrarily choosing one version.
This "always accept writes, reconcile later" philosophy enables Amazon to maintain high availability during traffic spikes, network issues, and infrastructure failures. The business impact is profound: a 1% drop in availability could cost millions in lost sales during peak periods.
The Hidden Cost of Strong Consistency
While eventual consistency presents challenges, strong consistency brings its own problems at scale:
Coordination overhead: Consensus protocols like Paxos and Raft require multiple network round-trips
Latency penalties: Waiting for distributed agreement increases response times
Availability risks: Partitioned nodes may become unavailable rather than serving stale data
Google's Spanner database achieves strong consistency at global scale through GPS-synchronized atomic clocks (TrueTime)—but even Google acknowledges this approach works best for specific workloads where consistency trumps all other concerns.
Practical Implementation Exercise
Start small by implementing a distributed counter using CRDTs. The code example shows how independent nodes can increment counters locally and automatically resolve conflicts when they sync—without coordination or locking.
This pattern can be extended to more complex data structures like sets, maps, and even text documents (as in collaborative editors). Libraries like Automerge and Yjs provide production-ready CRDT implementations for JavaScript applications.
Conclusion: Consistency Is a Spectrum, Not a Binary Choice
Eventual consistency isn't simply the absence of strong consistency—it's a deliberate engineering choice that prioritizes availability and partition tolerance. By understanding the trade-offs and implementing appropriate application-level solutions, you can build systems that are both highly available and functionally consistent from the user's perspective.
Remember: the goal isn't academic purity but building systems that provide the best possible user experience while scaling efficiently. Sometimes, "eventually" is not just good enough—it's exactly what your system needs.