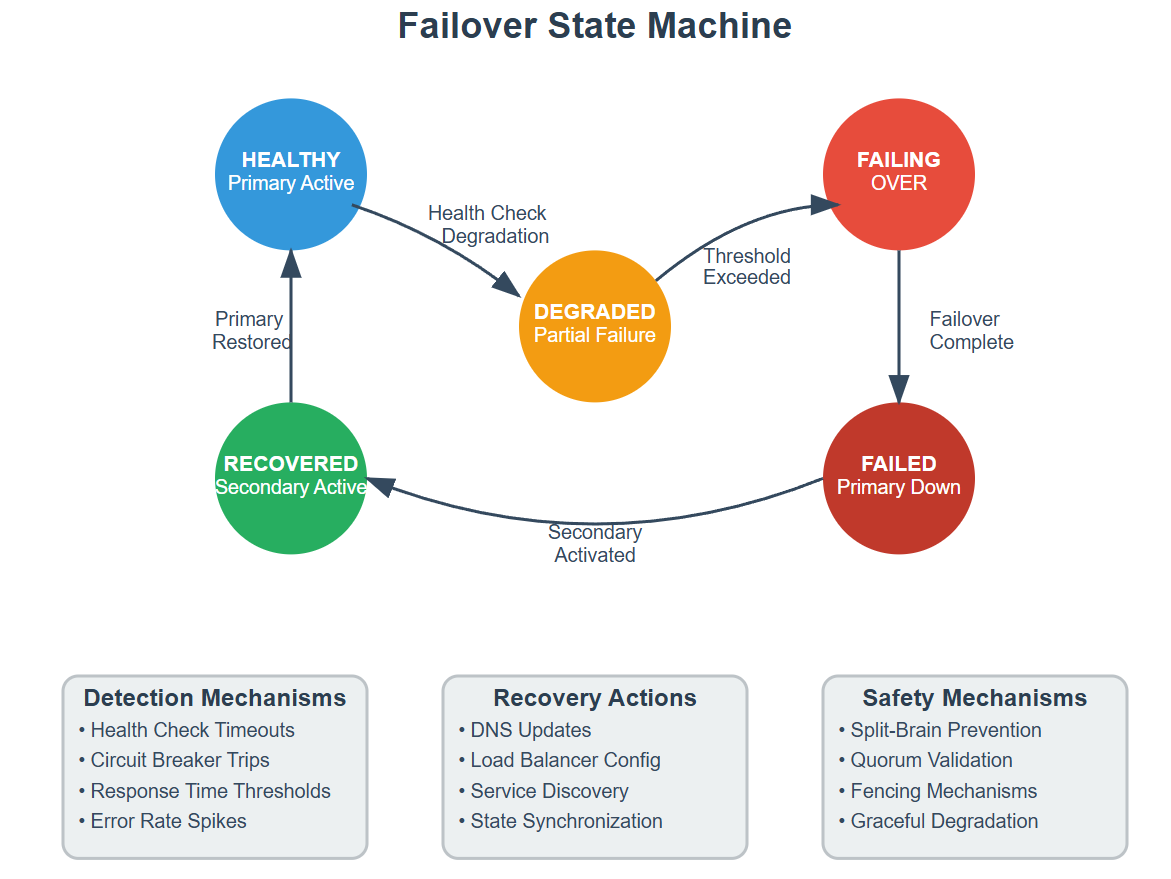
Failover Mechanisms in Action
Issue #136: System Design Interview Roadmap - Section 5: Reliability & Resilience
When Netflix Goes Down for 13 Minutes
In 2012, Netflix experienced a 13-minute outage that affected millions of users during prime streaming hours. The culprit? A single configuration change that disabled their failover mechanism. What should have been a seamless transition to backup systems instead cascaded into a complete service failure.
This incident taught the industry a crucial lesson: failover isn't just about having backup systems—it's about orchestrating the precise dance of detection, decision-making, and transition that keeps your users oblivious to infrastructure chaos.
What We'll Master Today
Failover Detection Patterns: How systems identify when primary components fail
Transition Orchestration: The critical moments between failure and recovery
State Synchronization: Keeping backup systems perfectly aligned
Cascading Failure Prevention: Why failover can sometimes make things worse
Youtube Video :
The Anatomy of Intelligent Failover