
Handling "Hot Keys" in Distributed Databases: Detection and Splitting Strategies
The Problem That Silently Kills Your Database
Your Redis cluster is running fine—CPU at 12%, memory comfortable, latency in single-digit milliseconds. Then one shard starts spiking: 98% CPU, 800ms p99, timeouts cascading into your application tier. Every other shard is idle. You’ve hit a hot key.
A hot key is a single cache or database key receiving a disproportionate share of traffic. In a distributed system where data is partitioned by key hash, one key always maps to one node. If that key is
product:iphone16-produring a product launch, that single node absorbs all reads and writes for it—regardless of how many nodes are in your cluster. More nodes don’t help. This is a partitioning problem, not a capacity problem.
Core Concept: Why Distribution Fails at Extremes
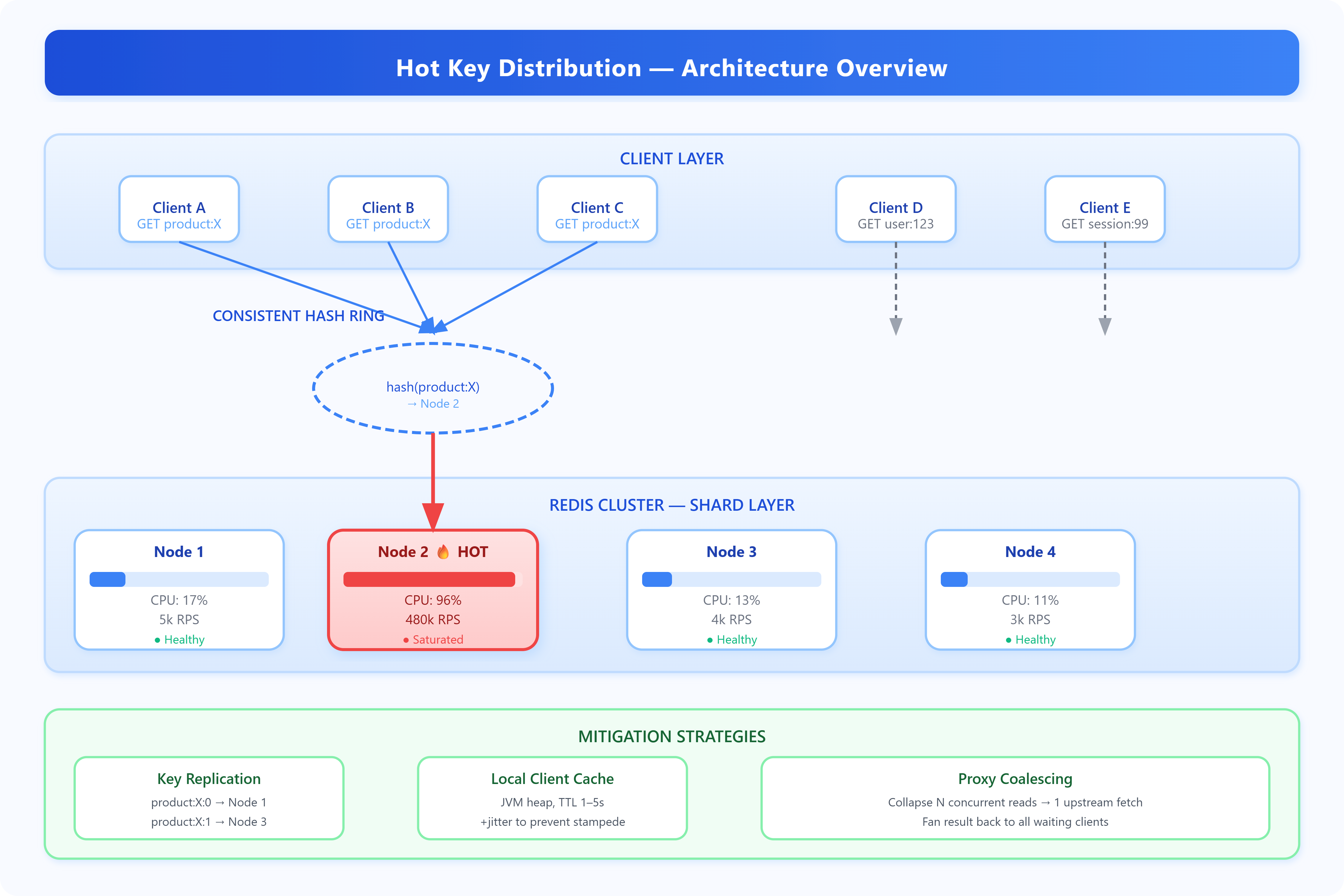
Distributed databases partition data using consistent hashing or range-based sharding. The goal is uniform distribution across nodes. This works when access patterns are uniform—but real traffic is never uniform. Power-law distributions (Zipf’s law) govern most real-world access patterns: a small percentage of keys receive the vast majority of requests.
