Immutable Infrastructure: Why You Should Never Patch Production Servers
Introduction
Your on-call rotation fires at 2 AM. A CVE dropped six hours ago, and your security team wants the patch deployed to 400 production nodes before morning. One engineer starts SSHing into boxes one-by-one. Another runs Ansible. A third realizes the first 50 boxes now have a slightly different kernel version than the rest. By dawn, you have a fleet that can’t be described accurately by any manifest, and the next incident will be twice as hard to debug because you no longer know what’s actually running.
That is the mutable infrastructure trap, and immutable infrastructure exists specifically to make that scenario impossible.
What Immutable Infrastructure Actually Means
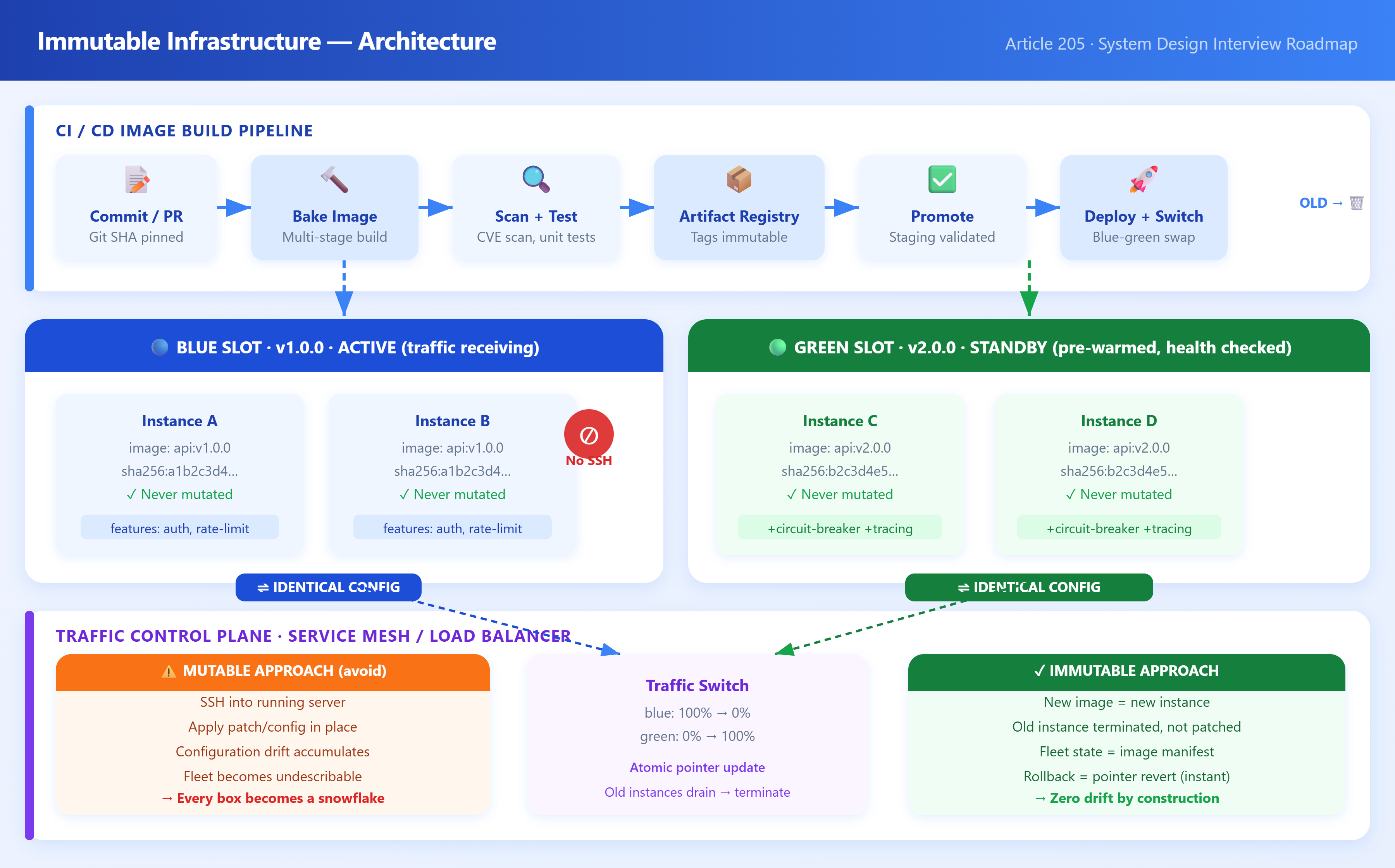
The word “immutable” is borrowed from functional programming: once a value is created, it never changes. Applied to servers, it means: once a machine image is baked and deployed, that instance is never modified. No SSH sessions. No config patches. No live package upgrades. If something needs to change—a new config value, a library update, a bug fix—you build a new image, replace the old instances, and terminate them.
The operational model becomes:
Build: Code change triggers a CI pipeline that bakes a new OS image (AMI, container image, VM snapshot). Every dependency is pinned and installed fresh.
Test: The image is validated in a staging environment that mirrors production.
Deploy: New instances launch from the validated image. Traffic shifts via load balancer or service mesh.
Terminate: Old instances drain connections and are destroyed. No orphan configs survive.
This is fundamentally different from Ansible playbooks or Chef recipes that mutate existing machines. Those tools are applying changes to an unknown prior state. Immutable infrastructure eliminates the prior state entirely.
The underlying insight: configuration drift is cumulative and invisible. Every hotfix applied directly to a server, every manually tweaked sysctl, every “temporary” cron job added during an incident—these accumulate over months until your fleet is a snowflake collection where no two boxes are identical. Automated tools can’t reliably detect what they didn’t apply. Immutable infrastructure makes drift structurally impossible because instances are never modified, only replaced.
Replacement vs. In-Place Update: When you replace rather than patch, you also solve the partial-failure problem. A rolling patch across 400 nodes can leave you in a mixed state if it fails halfway. A rolling image replacement can be rolled back atomically: keep old instances, shift traffic back, terminate new ones.
Image baking vs. runtime configuration: There’s an important nuance. Some configuration—environment-specific secrets, feature flags, endpoints—should not be baked into an image (that would mean a different image per environment). The split is: infrastructure configuration goes into the image; application configuration is injected at runtime via environment variables or a secrets manager. This keeps images environment-agnostic while still preventing runtime mutation.
Immutable does not mean stateless: Stateless application tiers are the most natural fit, but databases and stateful services can participate too. The data plane (the database files) lives on persistent volumes that survive instance replacement; the control plane (the database binary, OS, config files) is replaced via the same image pipeline.