
Indexing Strategies: B-Trees, Hash Tables, and R-Trees
Issue #24 of "System Design Interview Roadmap" - Part II: Data Storage
Checkout our “System Design Roadmap Course”, Trusted by 32000+ Engineers.
The Hidden Architecture Behind Every Query
Last week, I was debugging a performance issue for a client whose search functionality had slowed to a crawl. Their database had grown from thousands to millions of records, and what once took milliseconds now took seconds. The culprit? Missing indexes. It reminded me how easy it is to take these fundamental data structures for granted until they become your bottleneck.
Why Indexing Matters
Imagine searching for a name in a 1,000-page phone book without an alphabetical index. You'd have to scan every page—an O(n) operation. This is precisely what happens in a database full table scan. Indexes are the difference between your query returning in 3ms versus 3000ms, between a responsive application and frustrated users.
But not all indexes are created equal. Each type serves different query patterns and makes specific trade-offs. Let's explore these trade-offs in depth.
B-Trees: The Workhorse of Database Indexing
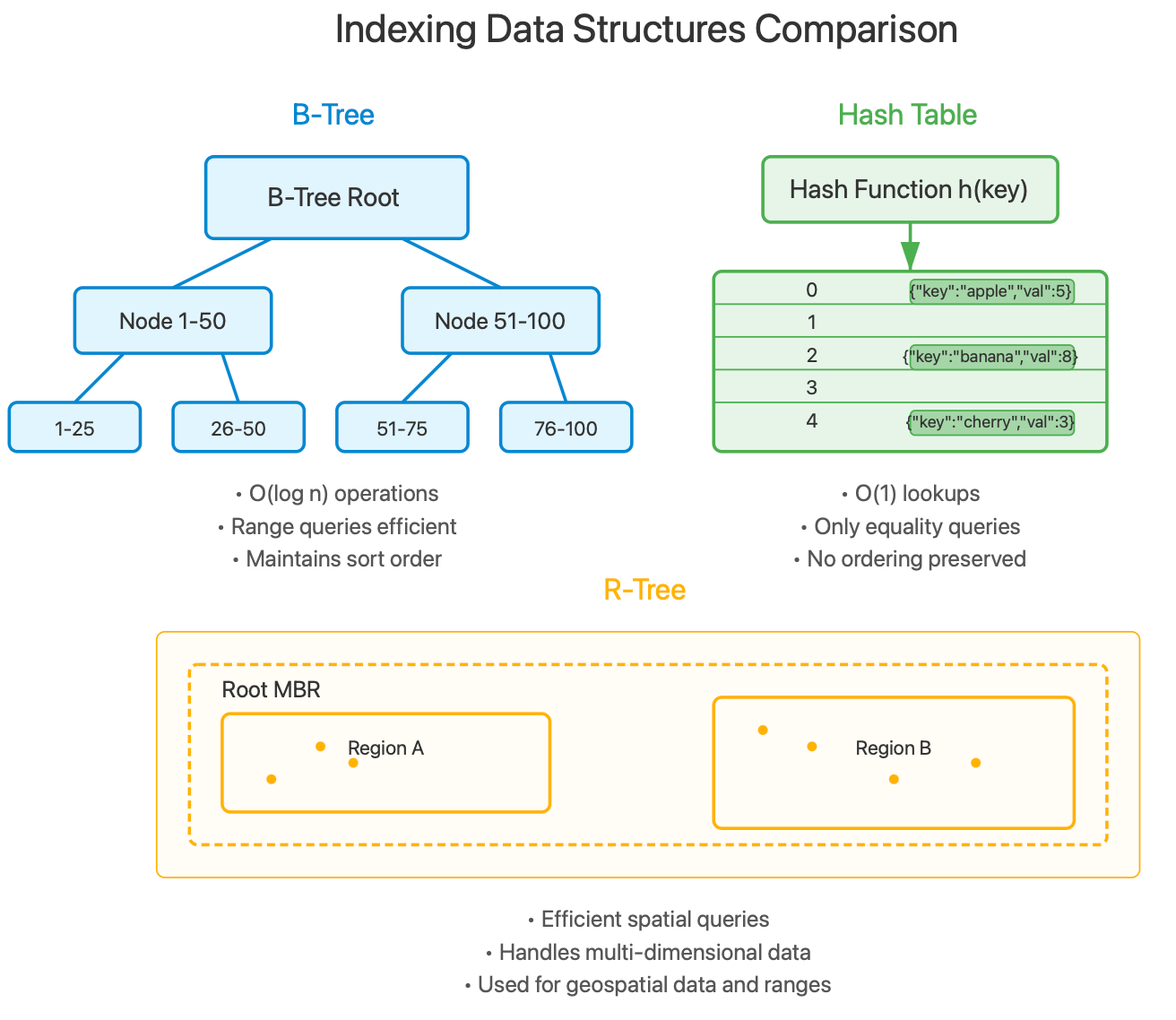
B-Trees (and their variant B+ Trees) are the backbone of most relational databases. Unlike binary search trees that can degenerate with sequential inserts, B-Trees maintain balance through a self-adjusting structure.
How B-Trees Work
B-Trees organize data in a hierarchical structure where:
Each node contains multiple keys and pointers
Keys within nodes are sorted
All leaf nodes exist at the same depth
The magic of B-Trees lies in their branching factor—each node can have many children, dramatically reducing tree height. A B-Tree with order 100 can store a billion records in just 3-4 levels.
The Non-Obvious Insights
What many engineers miss is how B-Trees optimize for modern hardware. Their node size (typically 4-16KB) aligns with disk page sizes and CPU cache lines. When you read one key, you're loading several adjacent keys "for free"—a brilliant example of locality of reference.
Another subtlety: most production B-Tree implementations use a fill factor (~70%), deliberately leaving space in each node. This apparent inefficiency actually improves write performance by reducing node splits during inserts.
Hash Tables: When Exact Match Is All You Need
Hash indexes shine for point queries—when you need exact matches on specific keys.
How Hash Tables Work
Hash functions transform keys into array indices, enabling O(1) lookups regardless of data size. Modern hash tables use sophisticated techniques like linear probing, robin hood hashing, or cuckoo hashing to handle collisions efficiently.
The Non-Obvious Insights
The catch with hash indexes? They only support equality comparisons. Range queries, sorting, or prefix searches aren't possible. This limitation explains why MySQL's MEMORY storage engine defaults to hash indexes, but PostgreSQL rarely uses them.
What's less understood is how hash tables perform under high concurrency. Their random access patterns can cause CPU cache thrashing in multi-threaded environments. I've seen systems where replacing a hash index with a B-Tree actually improved performance despite the theoretical O(log n) vs O(1) difference.
R-Trees: The Spatial Data Specialist
When your data exists in multiple dimensions—geographical coordinates, rectangles for computer vision, or time ranges—R-Trees become invaluable.
How R-Trees Work
R-Trees group nearby objects and represent them with their minimum bounding rectangle (MBR). These rectangles can overlap, creating a hierarchy that enables efficient spatial queries.
The Non-Obvious Insights
The brilliance of R-Trees is how they handle the "curse of dimensionality." Traditional B-Trees become inefficient beyond one dimension, but R-Trees maintain reasonable performance even with 3-5 dimensions.
What's rarely discussed is R-Tree variants' impact on real-world performance. PostgreSQL's GiST implementation uses an R-Tree variant that sacrifices some theoretical optimality for better concurrency and write performance. This pragmatic compromise often yields better results than academically "purer" approaches.
Indexing Data Structures Comparison
Practical Implementation Strategies
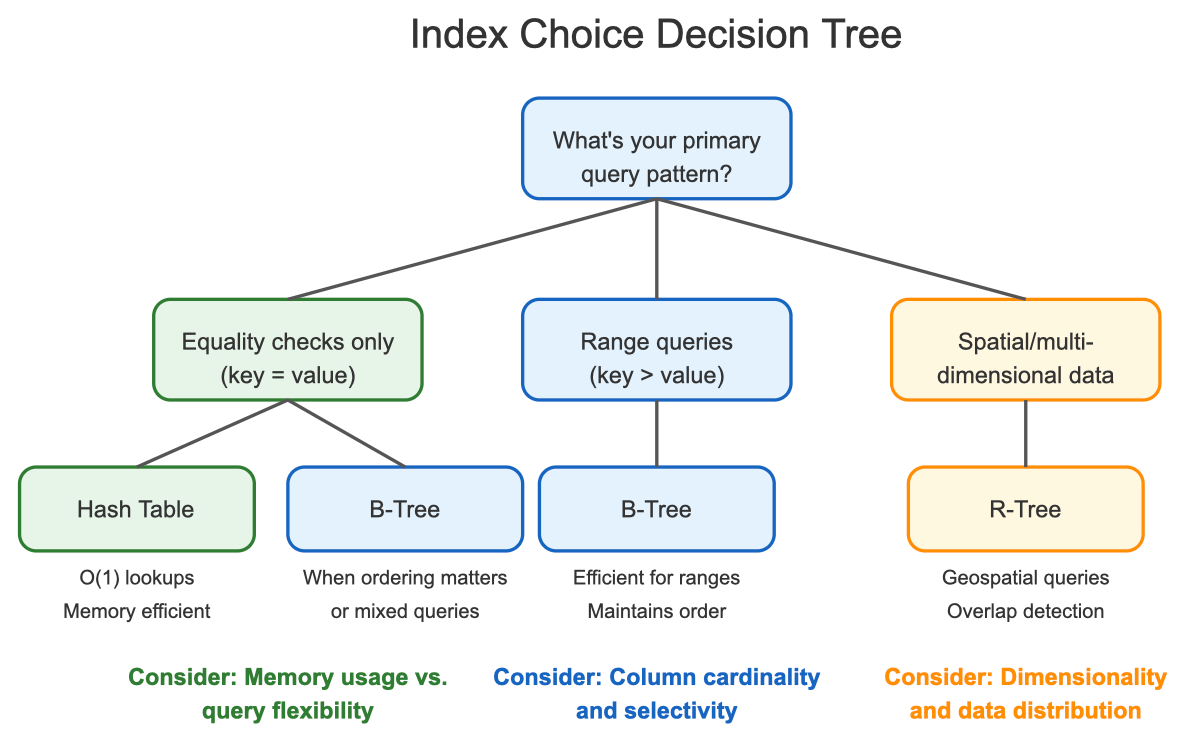
When should you use each index type? The answer depends on your query patterns and data characteristics:
B-Trees are your default choice for most scenarios, especially for:
General-purpose indexing with range queries
Sorted data access requirements
Complex queries with multiple conditions
Hash tables excel when:
You only need equality comparisons (key = value)
Memory usage is prioritized over versatility
You're implementing an in-memory cache
R-Trees become essential when:
Working with spatial data (GIS, maps)
Implementing time-range overlaps
Building recommendation systems based on multi-dimensional similarity
Real-World Production Optimizations
At scale, how you configure indexes matters as much as which type you choose:
Partial Indexing
One of my favorite techniques is partial indexing—including only a subset of rows. PostgreSQL's implementation allows expressions like:

This drastically reduces index size while maintaining performance for hot data. I've seen this reduce a 500GB index to 50GB with no perceptible performance impact for current queries.
Composite Indexing Strategies
The ordering of columns in composite indexes follows the "left-most prefix" rule. When designing these:

This index helps queries filtering on:
statusalonestatus AND last_login_date
But not those filtering on last_login_date alone. The most selective column should typically come first unless your query patterns dictate otherwise.
Index Choice Decision Tree
The Battle-Tested Rule of Thumb
After optimizing hundreds of databases, my rule of thumb remains: index for your queries, not your data. Analyze your actual query patterns before choosing indexes. I've seen teams add dozens of indexes trying to cover every possible query, only to degrade overall performance due to write amplification.
Remember, each index comes with maintenance costs:
Write amplification (every insert/update affects all indexes)
Storage overhead
Increased backup/restore times
For high-write systems processing millions of writes per second, consider these advanced techniques:
Time-partitioned indexes: Create separate indexes for different time ranges and drop old ones
Asynchronous indexing: Use write-optimized storage (e.g., LSM trees) and build indexes asynchronously
Approximate indexes: For analytics, bloom filters or count-min sketches can provide "good enough" results with minimal overhead
Bringing It All Together
The right indexing strategy can mean the difference between a system that scales to millions of queries per second and one that collapses under load. When designing, remember:
B-Trees are versatile workhorses ideal for most scenarios
Hash tables provide unbeatable performance for exact-match queries
R-Trees unlock efficient spatial and multi-dimensional queries
But perhaps the most important lesson is knowing when not to index. Every index adds write overhead and increases complexity. The most elegant systems use the minimum number of carefully chosen indexes to satisfy their critical query patterns.
In our next article, we'll explore "Write-Ahead Logging and Crash Recovery" - the hidden mechanisms that keep your data safe even when servers crash mid-transaction.