
Kernel Tuning for High-Load Systems: File Descriptors, TCP Buffers, and Ephemeral Ports
The Wall Nobody Sees Coming
Your application is humming. Load balancer green. CPU at 30%. Memory comfortable. Then at 4 AM, on-call fires: thousands of connections timing out, upstream services unreachable, health checks failing — yet every metric dashboard looks normal. The culprit isn’t your code. It’s the operating system silently running out of file descriptors, exhausted ephemeral ports, or TCP buffers too small to fill a gigabit pipe. Kernel limits are invisible until they snap. This is what that looks like, and how to prevent it.
Core Concept: The Kernel as a Silent Resource Broker
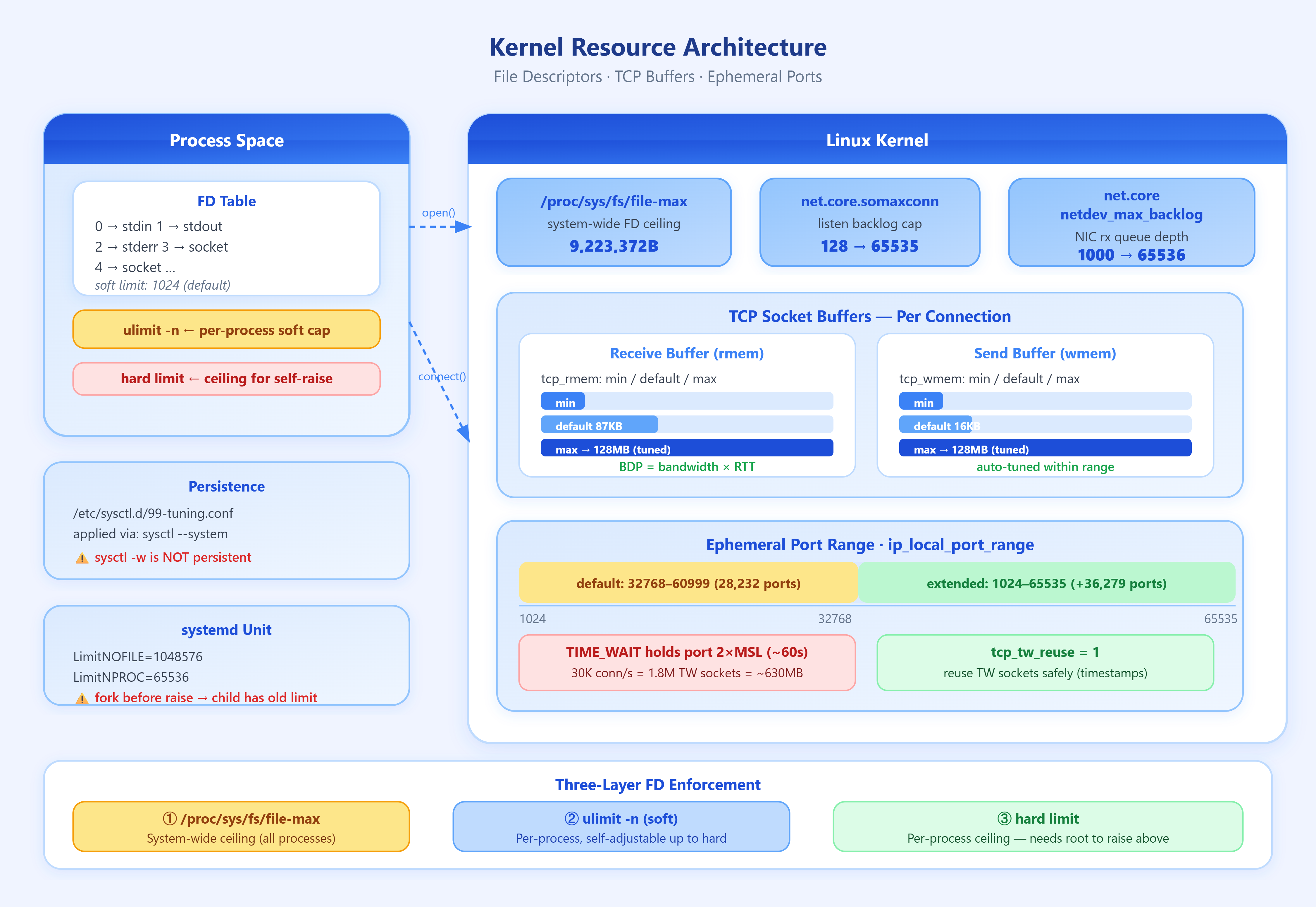
Every TCP connection your process opens requires a file descriptor (FD) — a kernel-managed integer handle. The same FD table also tracks open files, sockets, pipes, and device handles. The default limit on most Linux distributions is 1,024 per process (
ulimit -n). A single Nginx worker handling 10,000 connections needs 10,000+ FDs. If the limit is 1,024, the 1,025thaccept()call returnsEMFILE: Too many open files— silently dropped from the application’s perspective unless you instrument for it.
The three-layer limit model: Linux enforces FD limits at three levels simultaneously. The system-wide hard cap lives in /proc/sys/fs/file-max. The per-process soft limit is the one ulimit -n reports. The per-process hard limit is the ceiling a process can raise its own soft limit to without root. All three must be in alignment. Raising one without the others produces confusing partial failures: the process can’t open more FDs even though file-max looks healthy.
TCP buffers and throughput math: Each established TCP socket has a send buffer and receive buffer allocated in kernel memory — defaulting to 87KB receive (net.core.rmem_default) and 16KB send (net.core.wmem_default) on stock kernels. Buffer size directly determines throughput on high-latency links via the bandwidth-delay product (BDP): a 1 Gbps link with 50ms RTT requires 1,000,000,000 × 0.05 / 8 = 6.25 MB per connection to keep the pipe full. A 87KB buffer caps that connection at ~14 Mbps regardless of link speed. On AWS cross-region or trans-oceanic connections, under-buffered TCP is a consistent, measurable bottleneck.
The relevant kernel parameters:
net.core.rmem_max/net.core.wmem_max— per-socket maximums the application can requestnet.ipv4.tcp_rmem/net.ipv4.tcp_wmem— kernel’s auto-tuning range (min, default, max)net.core.netdev_max_backlog— packets queued when NIC receives faster than the kernel processes
Ephemeral port exhaustion: Outbound connections require a source port. The kernel allocates from the ephemeral range, default 32768–60999 on Linux — 28,232 ports. Each connection to the same destination IP:port consumes one 4-tuple (src_ip, src_port, dst_ip, dst_port). A service making 30,000 outbound connections per second to a single backend (common in reverse proxies, API gateways, or connection pools) will exhaust this range and start receiving EADDRNOTAVAIL. The fix is expanding the range via net.ipv4.ip_local_port_range to 1024–65535 (64,511 ports) and enabling net.ipv4.tcp_tw_reuse to recycle TIME_WAIT sockets safely.
TIME_WAIT itself is intentional — the kernel holds closed connections for 2×MSL (typically 60 seconds) to prevent delayed packets from poisoning new connections on the same 4-tuple. At 30K connections/second, that’s 1.8 million simultaneous TIME_WAIT entries. Each consumes ~350 bytes of kernel memory — 630MB just for state. tcp_tw_reuse allows reuse for outbound connections when timestamps confirm no stale data, eliminating the explosion without compromising correctness.
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
