Push vs. Pull Architectures in Real-Time Systems: When to Poll and When to Push
Introduction
Imagine you’re building a stock trading dashboard. Every millisecond, thousands of price updates flood in. Do you have clients constantly asking “Any updates yet? How about now?” (polling), or do you push updates the instant they arrive? This seemingly simple choice cascades into profoundly different system architectures, each with failure modes that can cost millions.
The Fundamental Divide
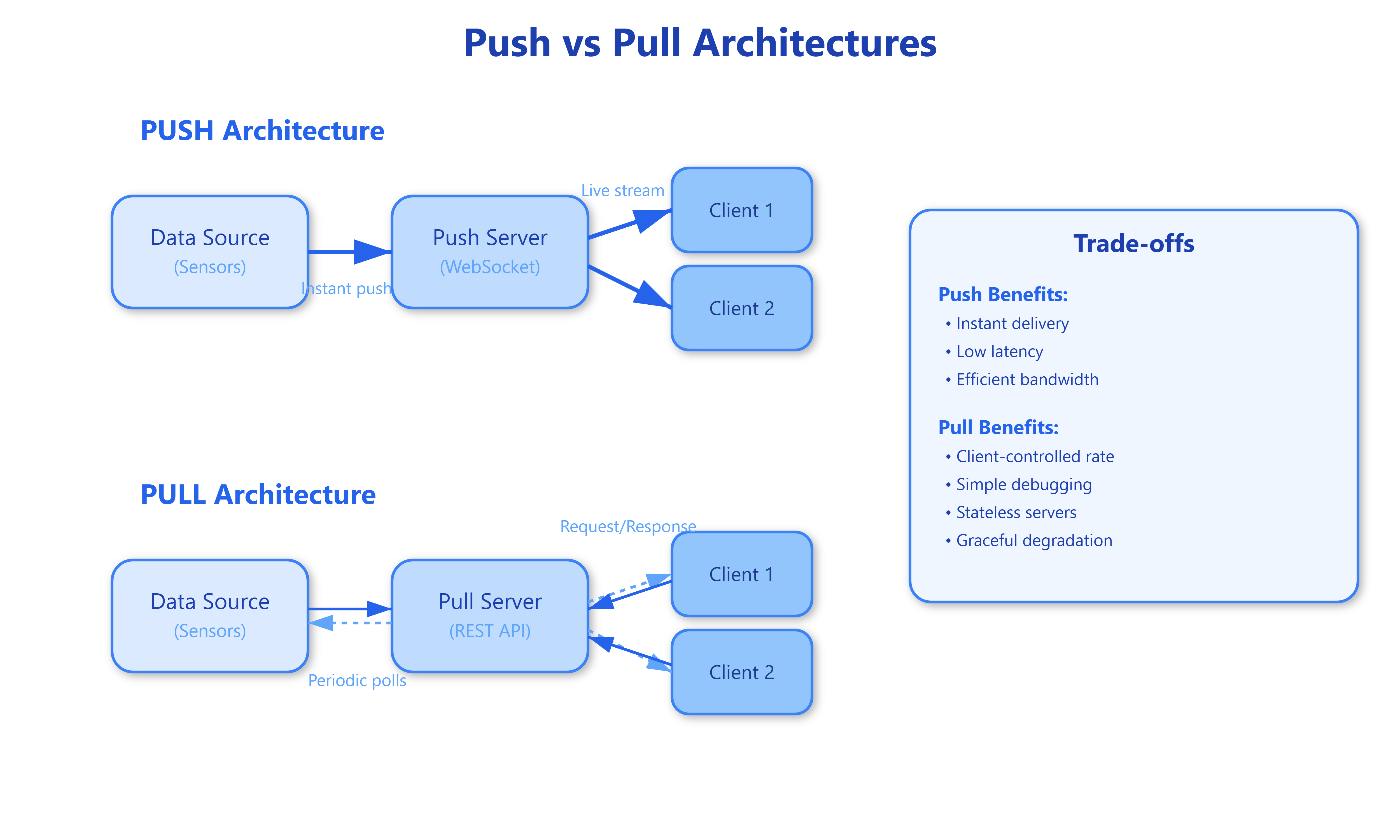
At its core, the push-pull decision determines who controls the data flow. In pull architectures, consumers request data when they need it—like checking your mailbox. In push architectures, producers send data immediately when it’s available—like getting notifications on your phone.
Pull systems work through periodic polling: clients send requests at fixed intervals (every 100ms, 1 second, etc.) asking “got anything new?” The server responds with either new data or an empty response. This creates a request-response cycle where the client drives the interaction rhythm. The beauty lies in its simplicity—HTTP, the backbone of the web, is fundamentally a pull protocol.
Push systems invert this control. The server maintains persistent connections (WebSockets, Server-Sent Events, or long polling) and transmits data the moment it’s generated. Clients don’t ask; they receive. This eliminates polling overhead but introduces connection management complexity—servers must track thousands or millions of active connections, each consuming memory and file descriptors.
The latency characteristics differ dramatically. Pull systems exhibit predictable but potentially stale data—if you poll every second, your worst-case latency is 1 second. Push systems deliver immediate updates but unpredictable load—a sudden burst of events can overwhelm consumers who can’t process fast enough.
Why This Matters: The Hidden Costs
Common Knowledge:
Push seems obvious for real-time systems—why wait when you can send instantly? But this overlooks critical failure patterns.
Rare Knowledge:
Push architectures create back-pressure problems that pull systems avoid naturally. When a push system generates events faster than consumers can process them, where do those events queue? At the producer (server memory fills up), in the network (TCP buffers overflow), or at the consumer (client crashes)? Netflix discovered this painfully with their real-time recommendation system—pushing updates to millions of concurrent streams caused cascading failures when recommendation algorithms spiked.
Advanced Insight:
Pull architectures enable client-controlled throttling. A struggling client simply polls less frequently. Push requires sophisticated flow control (reactive streams, TCP windowing, application-level acks) to prevent overwhelming slow consumers. Google’s Pub/Sub and Apache Kafka both implement pull-based consumption precisely for this reason—consumers fetch at their own pace, and the system never pushes more than they can handle.
Strategic Impact:
Connection storms during recovery can destroy push systems. After a network partition heals, thousands of disconnected clients simultaneously reconnect and re-subscribe. Each connection requires SSL handshake, authentication, and state synchronization. Slack’s 2020 outage illustrated this—when their WebSocket infrastructure recovered, the reconnection surge exceeded capacity. Pull systems degrade gracefully—clients simply continue polling with exponential backoff.
Implementation Nuance:
Hybrid architectures often win. Amazon’s CloudWatch uses push for critical alarms but pull for metric queries. Stripe’s webhook system pushes payment events but provides a pull API for reconciliation. The pattern: push for events that demand immediate action, pull for everything else.