
Retry Storms: Prevention and Mitigation
Issue #119: System Design Interview Roadmap • Section 5: Reliability & Resilience
The Problem We're Solving
When services get overwhelmed, our natural instinct is to retry failed requests. But this "helpful" behavior can transform a minor hiccup into a complete system meltdown. Retry storms happen when failed requests trigger more retries than the system can handle, creating an exponential death spiral.
What You'll Learn:
How retry storms multiply and destroy systems
Circuit breaker patterns that prevent cascading failures
Exponential backoff with jitter to spread load
Real-time detection and recovery strategies
Production-tested approaches from major tech companies
When Your Safety Net Becomes a Trap
Imagine you're running a food delivery service during peak dinner rush. Your payment service starts experiencing slight delays—maybe 2-3 seconds instead of the usual 200ms. Your well-intentioned retry logic kicks in across 1000 concurrent orders. Each retry doubles the load. Within seconds, your 1000 requests become 2000, then 4000, then 8000. Your payment service, already struggling, gets completely overwhelmed. What started as a minor hiccup becomes a complete system meltdown.
This is a retry storm—when your failure recovery mechanism becomes the very thing that destroys your system.
The Anatomy of Destruction
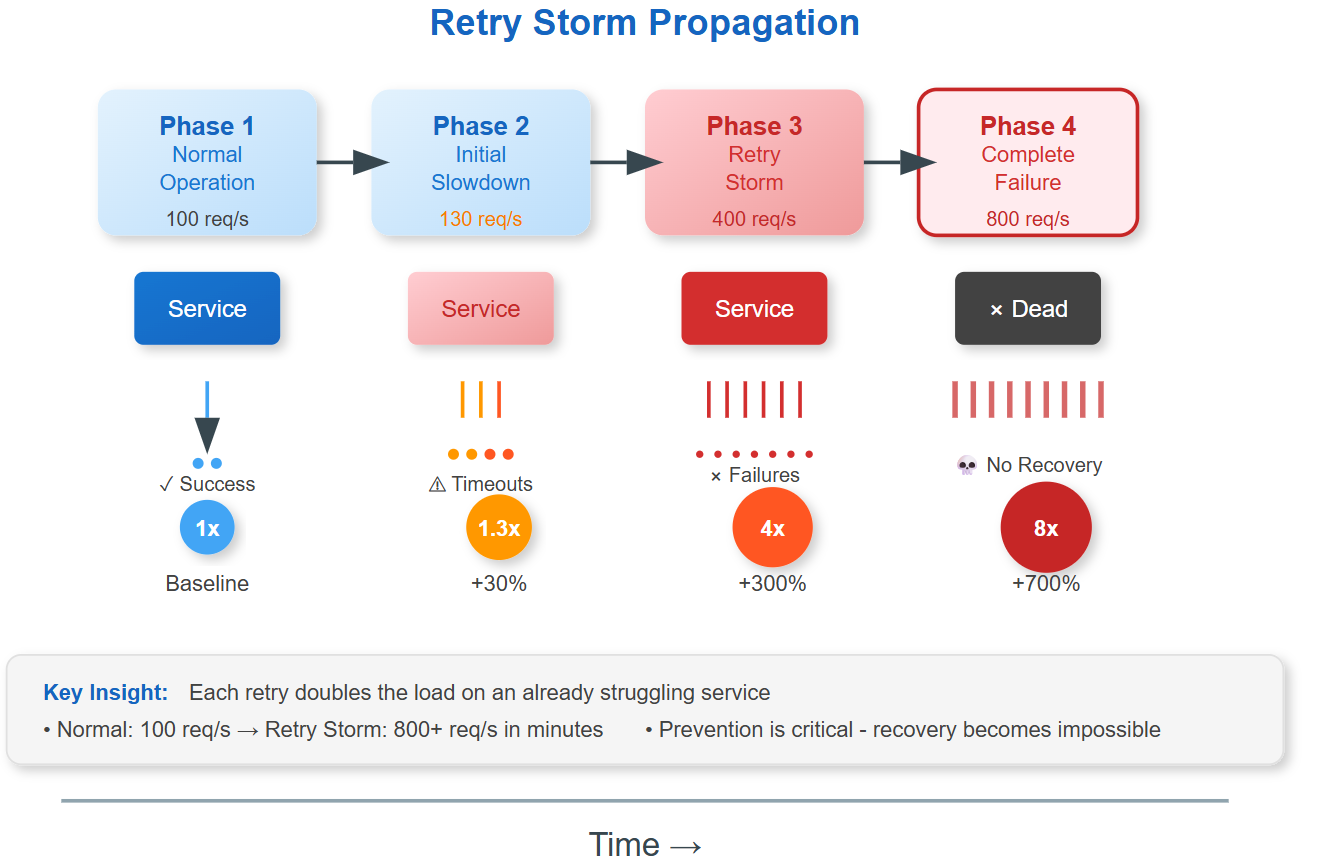
Retry storms happen when failed requests trigger retries faster than the system can recover. Here's the deadly pattern:
Phase 1: Initial Slowdown - A service starts responding slowly due to load, database issues, or network problems.
Phase 2: Retry Amplification - Clients timeout and retry, doubling the request load on an already struggling service.
Phase 3: Cascade Collapse - Increased load makes the service even slower, triggering more timeouts and retries in an exponential death spiral.
Phase 4: Complete Failure - The service becomes completely unresponsive, but retries continue, preventing any chance of recovery.
The Hidden Multiplier Effect
