
Runbooks: Standardizing Operational Procedures
Issue #131: System Design Interview Roadmap • Section 5: Reliability & Resilience
Working Code Demo:
What We'll Learn Today
Transform chaotic incident response into predictable, repeatable procedures
Design runbooks that scale from startup to enterprise-level operations
Integrate runbooks with automation systems for faster incident resolution
Build a production-ready runbook management system with real-time execution tracking
The 3 AM Phone Call That Changed Everything
Imagine you're awakened by an alert: your payment system is down, affecting thousands of transactions. Your drowsy teammate starts frantically Googling last month's similar issue while customers flood social media with complaints. This exact scenario cost one e-commerce company $2.3 million in revenue during a Black Friday outage.
The difference between companies that recover in minutes versus hours isn't technical superiority—it's having standardized operational procedures that anyone can execute under pressure. Welcome to the world of runbooks: your system's instruction manual for surviving chaos.
Why Traditional Documentation Fails Under Pressure
Most teams confuse runbooks with generic documentation. Traditional docs explain what systems do; runbooks prescribe how to respond when systems fail. The distinction becomes critical when your database is throwing connection errors at 2 AM and your senior DBA is unreachable.
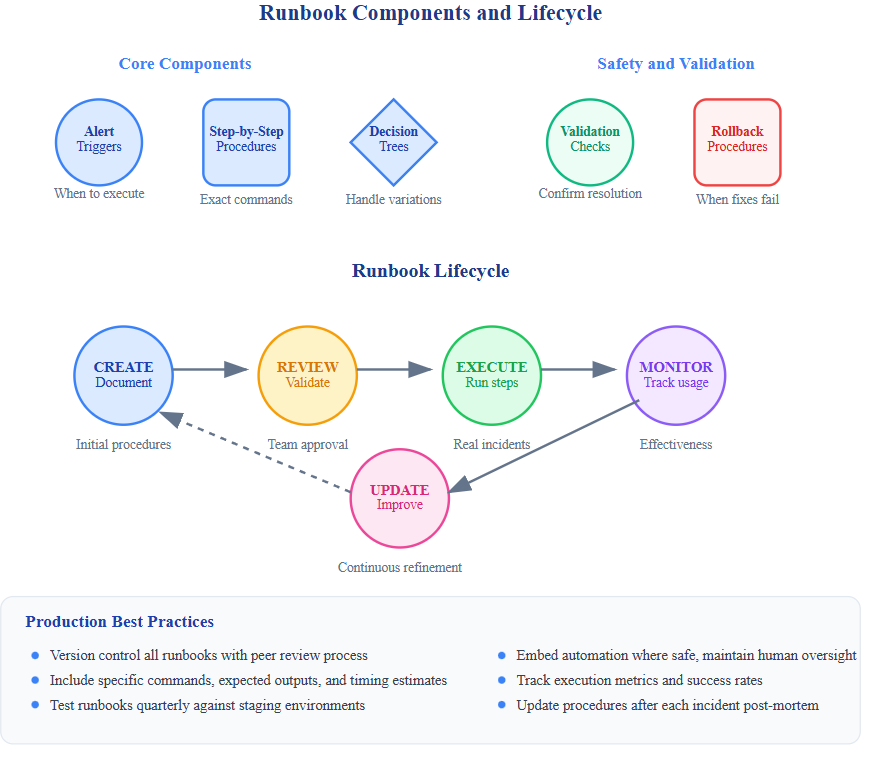
Effective runbooks contain five essential elements: clear triggers that define when to execute, step-by-step procedures with specific commands, decision trees for handling variations, rollback instructions for when fixes fail, and validation checkpoints to confirm resolution.
The Netflix Runbook Revolution
Netflix's engineering team discovered that 80% of their incidents followed predictable patterns. Instead of reinventing solutions each time, they created over 200 standardized runbooks covering everything from API gateway timeouts to recommendation service degradation.
Their breakthrough insight: runbooks aren't just troubleshooting guides—they're executable automation scripts with human oversight. When their content delivery network experiences regional failures, engineers don't diagnose from scratch; they execute the "CDN Regional Failover" runbook that automatically redirects traffic while performing health checks.
Google's SRE Playbook Philosophy
Google's Site Reliability Engineering team treats runbooks as living code. Each runbook undergoes peer review, version control, and automated testing. Their "Database Recovery" runbook includes actual SQL commands, expected outputs, and automated validation scripts that verify database integrity post-recovery.
The key insight: runbooks should be executable by any team member, not just domain experts. Google's runbooks include context sections explaining why each step matters, enabling junior engineers to execute complex procedures while understanding the implications.
Building Production-Ready Runbooks
Structure for Success: Start each runbook with severity classification, estimated time to resolution, and required permissions. Include specific commands rather than vague instructions like "check the logs"—specify which log files, what to search for, and how to interpret results.
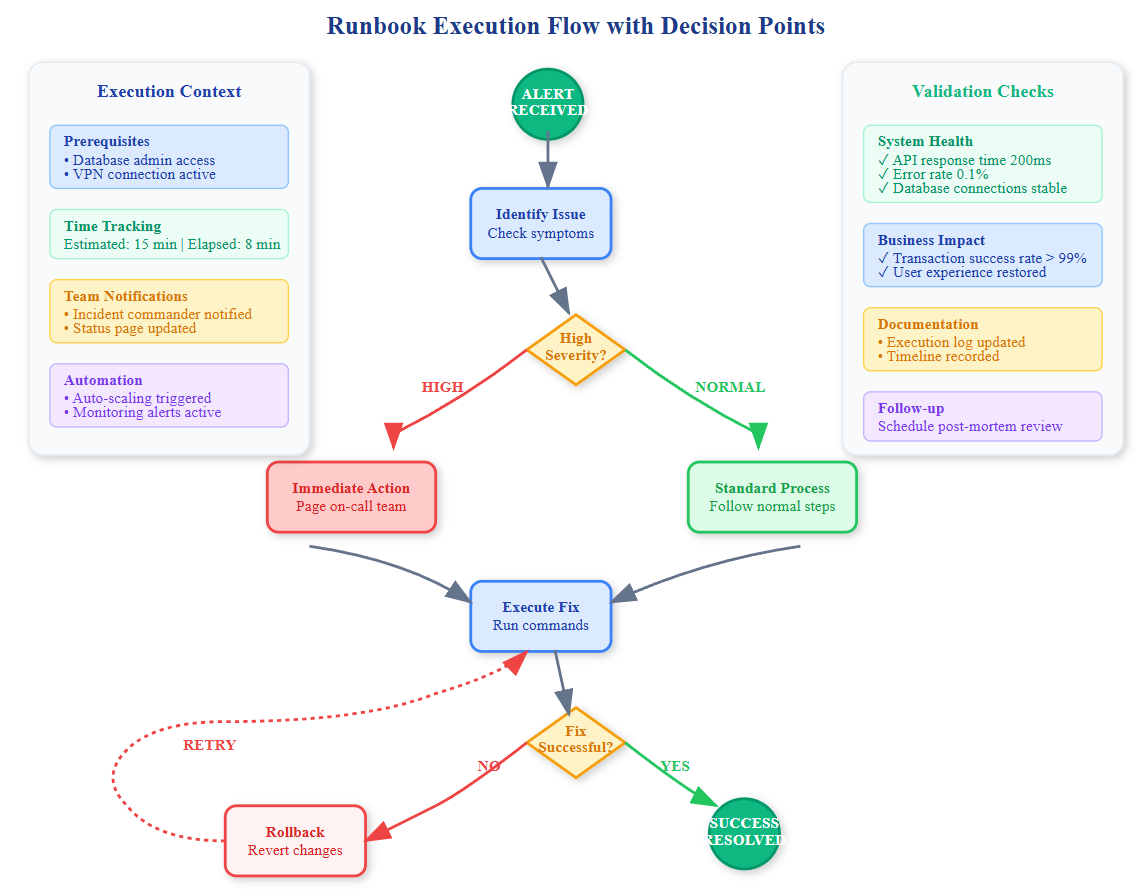
Decision Trees Matter: Real incidents rarely follow linear paths. Your runbook should include conditional logic: "If memory usage > 85%, execute scaling procedure; if < 85%, check network connectivity." These decision points prevent tunnel vision during high-stress situations.
Automation Integration: Modern runbooks blend manual oversight with automated execution. Critical steps like database failovers should include automation scripts that engineers can trigger with approval gates for safety.
The Hidden Complexity of Runbook Maintenance
The biggest runbook failure isn't technical—it's organizational. Systems evolve, but runbooks become stale. Airbnb solved this by implementing "runbook testing": quarterly exercises where teams execute runbooks against staging environments, updating procedures based on real execution results.
Smart teams embed runbook updates into their deployment process. When you modify a service's configuration, the deployment pipeline flags related runbooks for review. This prevents the common scenario where runbooks reference outdated commands or non-existent endpoints.
Advanced Patterns for Scale
Hierarchical Runbooks: Large organizations use tiered runbooks—Level 1 for common issues, Level 2 for complex diagnostics, Level 3 for architectural changes. This prevents overwhelming on-call engineers with unnecessary complexity while ensuring escalation paths exist.
Cross-Team Coordination: Distributed systems failures often span multiple services. Effective runbooks include communication templates for coordinating with dependent teams, status page updates, and customer communication scripts.
Metrics Integration: Production-grade runbooks include success metrics—not just "problem resolved" but quantitative measures like "API latency returned to <200ms" or "error rate dropped below 0.1%." This prevents false resolution declarations.
Implementation Strategy
Start with your three most frequent incident types—these often account for 70% of pages. Create basic runbooks covering symptom identification, immediate mitigation steps, and root cause investigation procedures.
Integrate runbooks into your incident management workflow. When creating incident tickets, automatically link relevant runbooks based on alert types. This reduces cognitive load during high-stress situations.
Test runbooks regularly through controlled exercises. Schedule monthly "fire drills" where teams execute runbooks against non-production environments, timing each step and identifying improvement opportunities.
Your Next Steps
Transform your next incident post-mortem into a runbook creation session. Instead of just identifying root causes, document the exact steps that resolved the issue. Include the commands you ran, the outputs you expected, and the decision points you encountered.
Build a simple runbook repository using version control. Each runbook should be a markdown file with structured sections: prerequisites, step-by-step procedures, validation commands, and rollback instructions. This approach scales from small teams to enterprise operations.
Hands-On Demo: Runbook Management System
Our demo creates a complete runbook management platform featuring:
Interactive Runbook Creator with template-based generation
Execution Tracking with real-time step completion monitoring
Automation Integration showing how runbooks trigger scripts
Team Collaboration features including comments and approvals
Analytics Dashboard tracking runbook usage and effectiveness
The system demonstrates how runbooks evolve from simple documentation into executable operational procedures that scale across teams and services.
GitHub Link:
https://github.com/sysdr/sdir/tree/main/Runbook_Development/runbook-management-systemKey Takeaways
Runbooks transform operational chaos into predictable, repeatable procedures. They're not just documentation—they're executable instructions that enable any team member to resolve complex issues under pressure.
The most successful engineering teams treat runbooks as living code: version-controlled, peer-reviewed, and continuously tested. This approach ensures procedures remain accurate as systems evolve while building organizational resilience that survives personnel changes.
Start small with your most common incidents, but think big about automation integration and cross-team coordination. Your future self (and your on-call teammates) will thank you when that 3 AM alert becomes a manageable, well-documented procedure rather than a panic-inducing mystery.