
Scaling Machine Learning Inference Systems
Issue #104: System Design Interview Roadmap • Section 4: Scalability
What We'll Learn Today
Picture this scenario: Your startup's recommendation engine powered by a transformer model just got featured on a major tech blog. Traffic surges from 100 requests per minute to 50,000 requests per second in thirty minutes. Your single GPU server, which comfortably handled development workloads, now crashes repeatedly as users experience 30-second timeouts. Sound familiar?
Today we'll master the art of scaling machine learning inference systems that can handle explosive traffic growth while maintaining sub-second response times. We'll build a production-grade inference platform featuring dynamic batching, model caching strategies, and intelligent load balancing that automatically adapts to demand patterns.
Here's what you'll walk away with: a complete understanding of inference bottlenecks most engineers miss, practical patterns used by companies processing billions of predictions daily, and a working system you can deploy immediately.
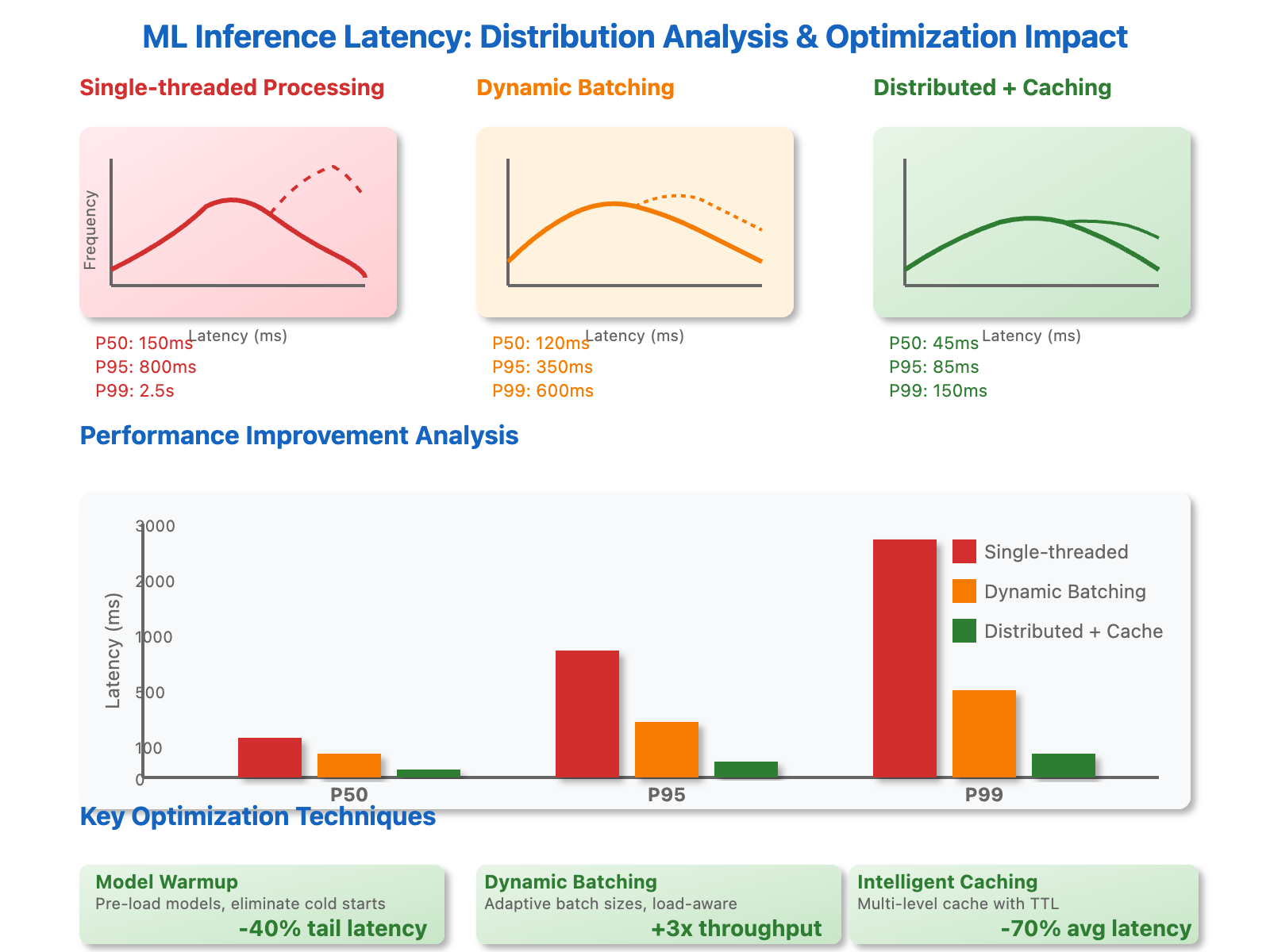
The Hidden Performance Killers in ML Inference
Most engineers approaching ML inference scaling focus on obvious bottlenecks like GPU memory or CPU cores. The real performance killers hide in plain sight, creating mysterious slowdowns that seem to defy hardware specifications.
🖼️ [ML Inference Performance Bottlenecks Architecture] Diagram showing the complete inference pipeline with hidden bottlenecks: memory allocation overhead, framework initialization costs, dynamic graph compilation, and data transfer latencies between CPU and GPU
