
System Design for AI-Powered Applications
Introduction
The explosion of AI-powered features has fundamentally changed how we architect systems. Companies like OpenAI handle 100 million requests daily, while Google’s Bard processes queries with sub-second latency. The challenge isn’t just serving models—it’s building infrastructure that balances cost, latency, and reliability at scale.
The Core Challenge: Inference Is Different
Traditional web services scale predictably: add servers, handle more requests. AI inference breaks this model. A single GPT-4 request consumes 1000x more compute than a database query. Latency varies wildly—200ms to 30 seconds for the same model. This unpredictability forces architectural decisions that differ from conventional services.
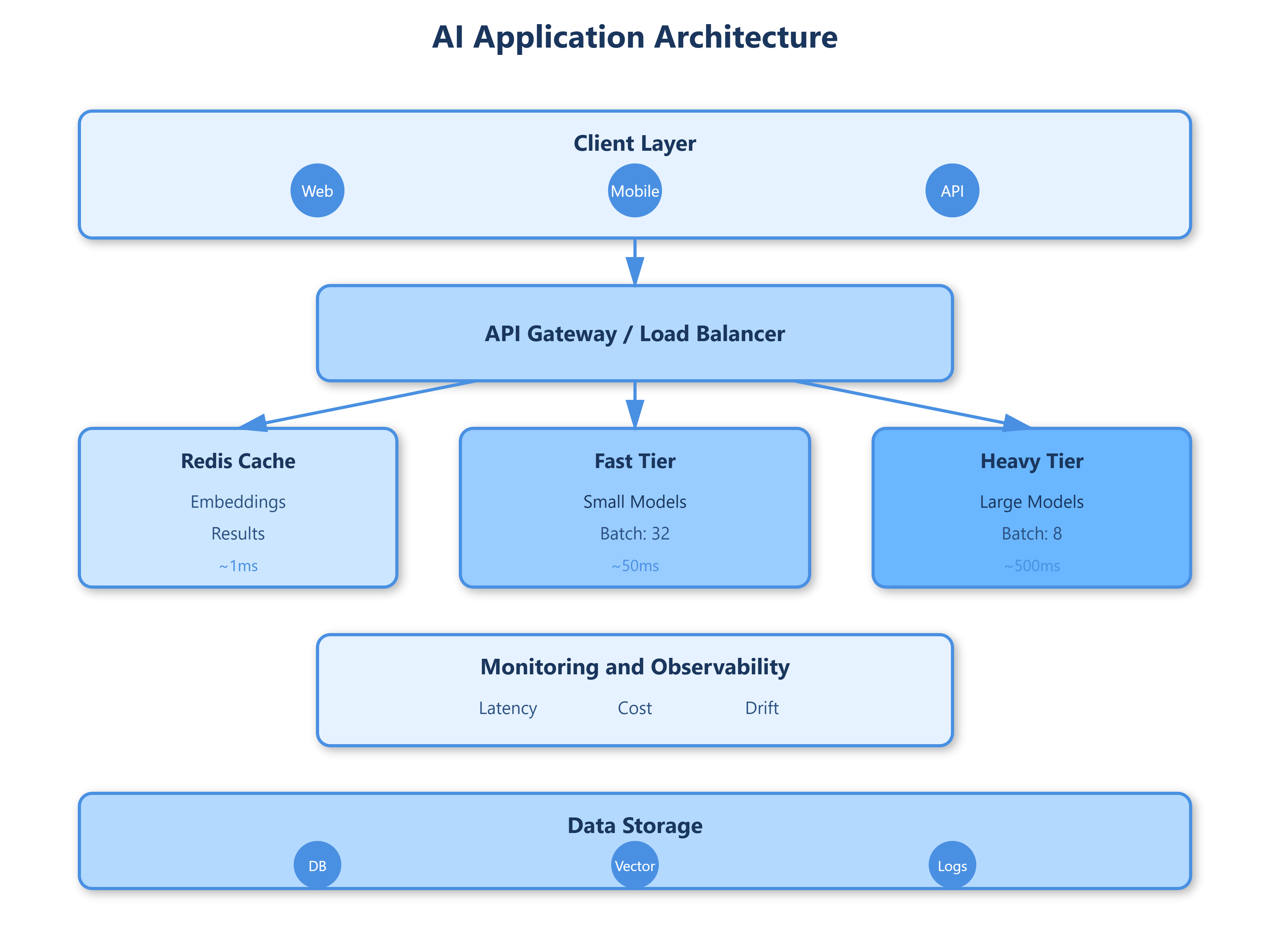
Netflix’s recommendation system demonstrates this reality. They run 15 different models simultaneously, each with different latency profiles. Their architecture separates fast path (cached embeddings, 50ms) from slow path (full model inference, 2-3 seconds). Users see instant results while heavy computation happens asynchronously.
Inference Optimization: The Hidden Multiplier
Model serving costs dominate AI application budgets. Anthropic revealed that 70% of their infrastructure spend goes to inference, not training. The optimization hierarchy matters: batching requests provides 10-40x throughput gains, quantization reduces memory by 4x, and caching eliminates 60-80% of redundant computations.
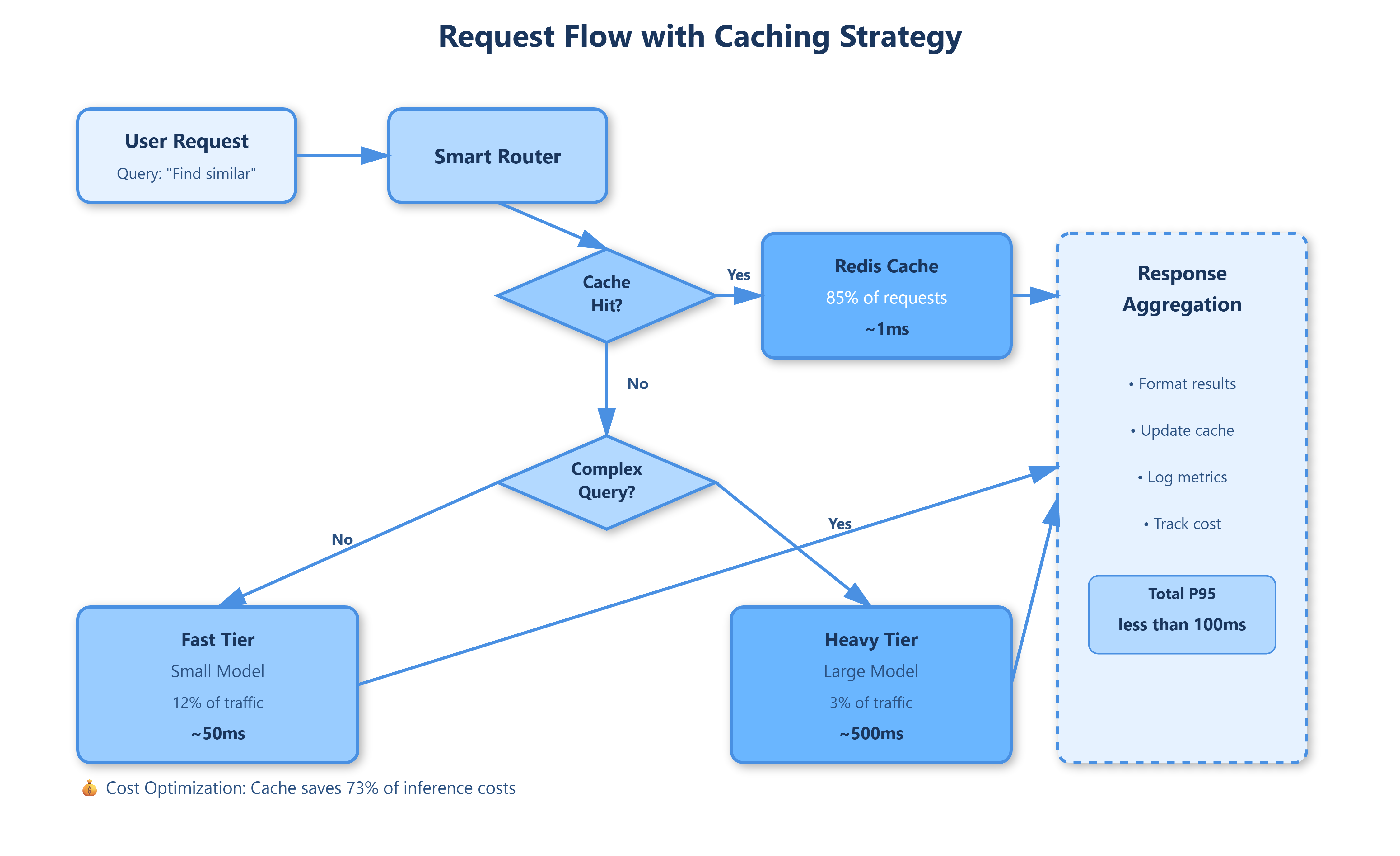
Stripe’s fraud detection illustrates this. They batch transactions in 10ms windows, achieving 25x higher throughput than individual inference. Their caching layer stores embeddings for 24 hours, cutting inference costs by 73%. The key insight: most AI requests exhibit high temporal locality—users repeat similar queries within hours.
The A/B Testing Complexity
Unlike traditional features, AI models can’t be tested with simple traffic splits. Model behavior emerges from training data distributions. Meta’s AI translation runs four model versions simultaneously, comparing not just accuracy but latency, cost, and user engagement. They discovered their largest model wasn’t always best—a 40% smaller model handled 80% of languages with 3x lower latency.
The testing infrastructure requires:
Shadow mode deployment: New models process real traffic without affecting users, building confidence before promotion
Metric correlation: Track business KPIs (conversion, engagement) alongside model metrics (accuracy, F1)
Cost-aware routing: Route expensive queries to larger models, simple ones to fast paths
Observability: Where Traditional Monitoring Fails
AI systems fail silently. A model degrading from 94% to 89% accuracy might go unnoticed in standard metrics. OpenAI’s ChatGPT outage in June 2023 stemmed from subtle drift in embedding space—requests succeeded but quality dropped.
Hugging Face’s production monitoring tracks:
Input distribution drift: Detect when live traffic diverges from training data
Latency percentiles by model tier: P99 latency for their largest models is 40x the median
Token consumption patterns: Unexpected spikes indicate prompt injection or abuse
The critical metric: cost per successful inference. This combines technical performance (latency, throughput) with business impact (completion rate, user satisfaction).
Production Patterns from the Field
Google’s Universal Sentence Encoder serves 100 billion embeddings monthly using a three-tier strategy: 85% of requests hit Redis cache (1ms), 12% use batch inference on GPU clusters (50ms), and 3% trigger expensive fine-tuned models (500ms+). This tier separation keeps P95 latency under 100ms while controlling costs.
The architectural principles that emerged:
Async-first design: Never block user requests on model inference
Graceful degradation: Serve cached/simpler models when primary models timeout
Cost circuit breakers: Hard limits on expensive model calls per user/hour
Building Your AI Infrastructure
GitHub Link
https://github.com/sysdr/sdir/tree/main/System_design_for_AI_Powered_App/ai-powered-appStart with embedding-based features—they’re 100x faster than generative models and solve 70% of AI use cases (search, recommendations, similarity). Add caching aggressively—in-memory stores like Redis reduce inference by 60-80%. Implement tiered models where fast approximations handle common cases.
The demo system shows a complete production-grade setup: model serving with batching, multi-tier caching, A/B testing framework, and real-time monitoring. You’ll see how request routing decisions impact latency and cost, experiencing the same trade-offs engineers face at companies serving millions of AI requests daily.
Key Takeaways
AI-powered applications require rethinking distributed systems fundamentals. Latency isn’t normally distributed. Costs scale non-linearly with traffic. Silent failures manifest as quality degradation, not errors. The companies succeeding at scale treat AI inference as a first-class concern in their architecture, not an afterthought bolted onto existing services.
Your production checklist: implement request batching, add multi-tier caching, monitor input distribution drift, and always have fallback paths when models fail or timeout. The future belongs to systems that make AI inference fast, cheap, and reliable.