Vector Databases Explained — How Pinecone and Milvus Handle High-Dimensional Data
When Text Search Stops Working
Your e-commerce search returns zero results for “running shoes for bad knees” because no product title contains that exact phrase. Your document store can’t surface the policy update most relevant to a user’s complaint, even though it’s clearly related. Your recommendation engine has no idea that a user who loves “Inception” might enjoy “Coherence.”
These failures share a root cause: traditional databases index exact values. A B-tree on a VARCHAR column matches “inception” or it doesn’t. It has no concept of semantic proximity. Vector databases exist to close that gap — storing and querying embeddings so that “similar meaning” becomes a first-class query operation.
Core Concept: What a Vector Database Actually Does
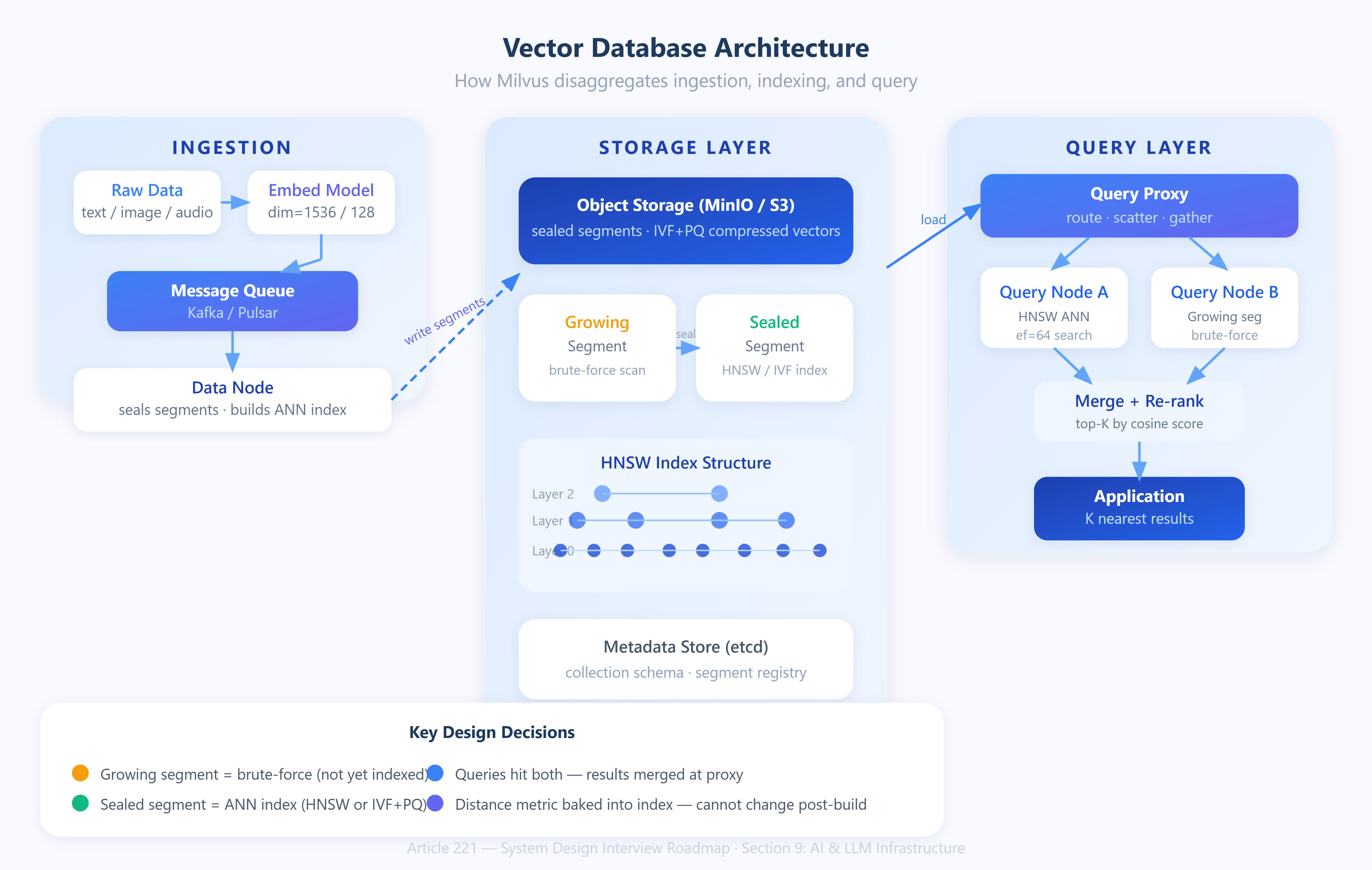
An embedding model (BERT, OpenAI’s
text-embedding-3-large, CLIP, etc.) converts your raw data — text, images, audio — into a dense float array. A sentence like “my knee hurts when I run” becomes a 1,536-dimensional vector. Geometrically, semantically similar things cluster together in that high-dimensional space.
A vector database stores those arrays and answers one primary query: given a query vector Q, return the K nearest stored vectors by some distance metric (cosine similarity, Euclidean distance, or inner product).
The naïve approach is brute-force: compute the distance between Q and every stored vector. At 100M rows and 1,536 dimensions, that’s 153.6 billion float operations per query — too slow for interactive latency.
Approximate Nearest Neighbor (ANN) indexes trade a small amount of recall for orders-of-magnitude faster lookups. Both Pinecone and Milvus are fundamentally ANN index managers at their core.
HNSW: The Dominant Index Structure
Hierarchical Navigable Small World graphs are the current standard. Think of it as a multi-layer skip list, but the links between nodes are based on embedding similarity rather than sorted order.
Layer 0 contains all nodes. Higher layers contain exponentially fewer nodes (probabilistic sampling).
Insertion places the vector at the appropriate layers, connecting it to its M nearest neighbors at each layer (M is a tunable parameter — typically 16–64).
Search enters at the top layer, greedily hops toward the query vector, then descends to lower layers for progressively finer traversal until Layer 0.
Search complexity is O(log N) in practice. The efConstruction parameter controls how many candidate neighbors are evaluated during index build (quality vs. build speed). The ef parameter at query time controls the dynamic candidate list size (recall vs. latency).
The non-obvious property: HNSW is not updatable without quality degradation. Deletions mark vectors as “deleted” but leave ghost nodes in the graph. After enough deletes, you need to compact — a full index rebuild.
IVF: The Alternative for Memory-Constrained Systems
Inverted File Index partitions the vector space into K Voronoi cells via k-means clustering. At query time, the search probes the
nprobenearest cluster centroids, then scans only those clusters. This dramatically reduces memory footprint compared to HNSW since you don’t store full graph adjacency.
Trade-off: if your query vector sits near a cluster boundary, the true nearest neighbor might be in an adjacent unprobed cluster. Recall degrades predictably as nprobe decreases.
IVF+PQ (Product Quantization) adds lossy compression of the stored vectors — splitting each vector into sub-vectors and replacing each with a codebook index. You can compress 1,536-dim float32 vectors (6KB each) to ~192 bytes with minimal recall loss. At 100M vectors, that’s the difference between 600GB and 19GB of index memory.